> For the complete documentation index, see [llms.txt](https://bemind.gitbook.io/neural/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://bemind.gitbook.io/neural/uchebniki-po-pandas-i-numpy/numpy/raspredelenie-normalnogo-gaussova-raspredeleniya-v-numpy-sluchainoe-normalnoe-v-numpy.md).
# Распределение Нормального (Гауссова) Распределения в Numpy (Случайное Нормальное в Numpy)
В этом уроке **вы узнаете, как использовать функцию Numpy random.normal для создания нормальных (или гауссовских) распределений**. Функция предоставляет вам инструменты, позволяющие создавать распределения с определенными средними значениями и стандартными распределениями. Кроме того, вы можете создавать распределения различного размера.
К концу этого урока вы узнаете:
* Что такое нормальное (гауссово) распределение?
* Как использовать функцию `numpy.random.normal()` для создания нормальных распределений
* Как указать среднее значение, стандартное отклонение и форму распределения
* Как построить графики распределения с помощью Seaborn
Оглавление
* [Что такое нормальное (гауссово) распределение?](#chto-takoe-normalnoe-gaussovo-raspredelenie)
* [Как использовать Numpy для создания нормального распределения](#kak-ispolzovat-numpy-dlya-sozdaniya-normalnogo-raspredeleniya)
* [Как построить нормальное распределение с помощью Seaborn](#kak-postroit-normalnoe-raspredelenie-s-pomoshyu-seaborn)
* [Как изменить среднее значение нормального распределения в Python Numpy](#kak-izmenit-srednee-znachenie-normalnogo-raspredeleniya-v-python-numpy)
* [Как изменить стандартное отклонение нормального распределения в Python Numpy](#kak-izmenit-standartnoe-otklonenie-normalnogo-raspredeleniya-v-python-numpy)
* [Как изменить форму нормального распределения в Numpy](#kak-izmenit-formu-normalnogo-raspredeleniya-v-numpy)
* [Заключение](#zaklyuchenie)
* [Дополнительные ресурсы](#dopolnitelnye-resursy)
### Что такое нормальное (гауссово) распределение?
Нормальное распределение описывает распространенное явление, которое возникает, когда данные распределены определенным образом. Это означает, что данные не смещены в какую-либо сторону, но и не рассыпаны хаотично. Фактически, они формируют кривую в форме колокола, аналогичную приведенной ниже диаграмме:
Нормальное распределени
Вы, возможно, думаете: "Как часто это может происходить?" На самом деле, *довольно часто*. Например, рост и вес людей в основном распределены нормально. Так же как артериальное давление, оценки за тесты и изделия, произведенные машинами.
Когда мы говорим о том, что данные распределены нормально, мы имеем в виду:
1. Они расположены вдоль среднего значения
2. Они следуют правилам, касающимся стандартных отклонений
На изображении выше темно-синие линии представляют собой 1 стандартное отклонение от среднего в обоих направлениях. Согласно гауссовскому распределению, \~68,2% значений будут находиться в пределах одного стандартного отклонения.
Если вы хотите научиться проверять, является ли распределение нормальным, ознакомьтесь с моим руководством по использованию Python для тестирования на нормальность
### Как использовать Numpy для создания нормального распределения
Функция `random.normal` в библиотеке numpy используется для создания массивов, которые соответствуют нормальному или Гауссовому распределению. Эта функция обладает высокой гибкостью, поскольку позволяет задавать различные параметры для формирования массива. За кулисами Numpy гарантирует, что полученные данные будут иметь нормальное распределение.
Давайте посмотрим, как работает функция:
```python
# Понимание синтаксиса random.normal()
normal(
loc=0.0, # Среднее значение распределения
scale=1.0, # Стандартное отклонение
size=None # Размер или форма вашего массива
)
```
Хотя функция имеет всего три параметра, она предоставляет значительные возможности для настройки возвращаемого массива. Давайте узнаем немного больше о этих параметрах:
* `loc=` представляет среднее значение (или центр) распределения и по умолчанию равно 0.0
* `scale=` представляет стандартное отклонение и по умолчанию равно 1.0
* Параметр `size=` немного сложнее. Он принимает либо целое число, либо кортеж целых чисел. Если передается число, создается одномерный массив заданного размера. Если передается кортеж, например (x, y), будет создан массив размером x \* y.
Давайте создадим ваш первый дистрибутив:
```python
from numpy.random import normal
norm = normal(size=20)
print(norm)
# Возвращает:
# [-0.96471102 0.97183671 0.64331032 0.17967547 1.13204258 0.82451325
# -0.15279955 1.07637854 0.4237334 -0.37220927 -1.63307194 0.40096688
# -0.36214115 -0.18937799 -0.43963889 -0.37077402 -0.20623217 -0.95767066
# 1.60089927 0.45036494]
```
В приведенном выше примере вы создали нормальное распределение из 20 значений, с центром вокруг среднего равного 0 и со стандартным отклонением равным 1.
В следующем разделе вы узнаете, как построить полученное распределение с использованием Seaborn.
### Как построить нормальное распределение с помощью Seaborn
В этом разделе вы узнаете, как визуализировать созданное вами распределение с помощью Seaborn. Seaborn специализируется на визуализации статистических распределений. В данном примере вы будете использовать функцию histplot, которая служит для визуализации распределений.
Давайте создадим вашу первую визуализацию:
```python
# Создание первой визуализации
# Импортируем необходимые библиотеки
from numpy.random import normal
import matplotlib.pyplot as plt
import seaborn as sns
# Генерируем случайные числа из нормального распределения
norm = normal(size=20)
# Строим гистограмму с наложенной кривой плотности
sns.histplot(norm, kde=True)
# Отображаем график
plt.show()
```
Это возвращает следующее изображение:
Вы можете подумать, что распределение действительно не выглядит нормальным. Это потому, что мы выбрали только 20 значений. Давайте создадим пример с 2000 значениями и посмотрим, как изменится визуализация:
```python
from numpy.random import normal
import matplotlib.pyplot as plt
import seaborn as sns
norm = normal(size=2000)
sns.histplot(norm, kde=True)
plt.show()
```
Это возвращает следующее изображение:
В следующем разделе вы научитесь изменять среднее значение нормального распределения с использованием функции random normal в Numpy.
### Как изменить среднее значение нормального распределения в Python Numpy
По умолчанию функция `random.normal()` в Numpy использует среднее значение 0. Часто возникает необходимость изменить это значение. Это легко сделать, используя аргумент `loc=`. Аргумент по умолчанию равен 0.0, но изменение его значения изменит среднее значение распределения.
Давайте воссоздадим приведенный выше пример, используя среднее значение 100:
```python
# Изменение среднего значения нормального распределения
# Импортируем необходимые библиотеки
from numpy.random import normal
import matplotlib.pyplot as plt
import seaborn as sns
# Генерируем случайные числа из нормального распределения с измененным средним значением
norm = normal(loc=100, size=2000)
# Строим гистограмму с наложенной кривой плотности
sns.histplot(norm, kde=True)
# Отображаем график
plt.show()
```
Это возвращает следующее распределение:
В этом случае распределение выглядит аналогично, но данные сосредоточены вокруг значения 100. В следующем разделе вы узнаете, как изменить стандартное отклонение нормального распределения.
### Как изменить стандартное отклонение нормального распределения в Python Numpy
Точно так же, как вы можете желать указать среднее значение вашего результирующего распределения, вы также можете захотеть изменить стандартное отклонение набора данных.
Это можно сделать, используя параметр `scale=`. Давайте изменим стандартное отклонение на 20.
```python
# Изменение стандартного отклонения нормального распределения
from numpy.random import normal
import matplotlib.pyplot as plt
import seaborn as sns
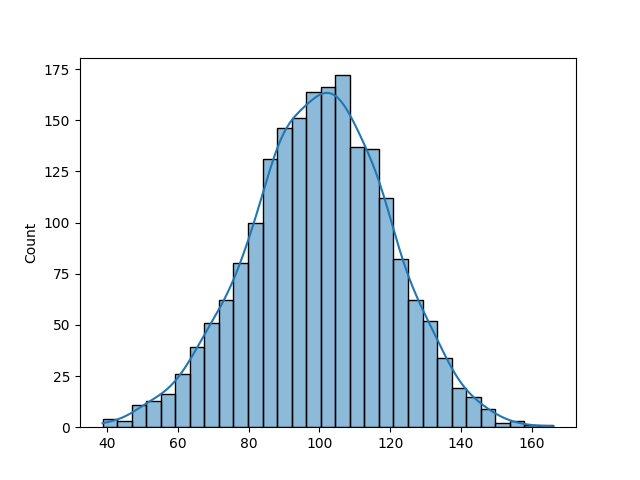
norm = normal(loc=100, scale=20, size=2000)
sns.histplot(norm, kde=True)
plt.show()
```
Это возвращает следующее распределение:
В следующем разделе вы узнаете, как изменить форму полученного массива.
### Как изменить форму нормального распределения в Numpy
Одной из удивительных особенностей функции `numpy.random` normal является то, что она позволяет легко определить форму получаемого массива. До сих пор мы указывали значение параметра `size` в виде целого числа.
Когда вы передаете кортеж целых чисел, это изменяет форму массива с одномерного на многомерный массив. Если вы передаете кортеж значений (2, 3), вы получите массив с двумя строками и тремя столбцами.
Результирующий массив будет иметь нормальное распределение. Давайте создадим пример, где мы создадим массив 2×10:
```python
# Изменение формы массива нормального распределения
from numpy.random import normal
norm = normal(loc=100, scale=20, size=(2,10))
print(norm)
# Возвращает:
# [[108.49943923 78.2338738 88.54610957 115.39467754 86.54653081
# 59.0665876 101.14148334 130.34385877 108.22246364 86.59464058]
# [110.07354478 129.55607744 76.92302147 147.73941769 153.69210309
# 90.90013017 105.71356503 100.57125782 90.44076092 93.29935961]]
```
### Заключение
В этом уроке вы научились использовать функцию normal модуля Numpy для создания нормального распределения. Вы узнали, как задать количество значений в массиве, среднее значение массива и стандартное отклонение массива с помощью этой функции. Также вы научились использовать Seaborn для визуализации этого распределения.
### Дополнительные ресурсы
Для изучения смежных тем ознакомьтесь с нижеприведенными учебными пособиями:
* NumPy для науки о данных в Python
* Учебное пособие по стандартному отклонению Python: объяснение и примеры
* Среднее значение Pandas: рассчитать среднее значение Pandas для одного или нескольких столбцов