# Изучение API стиля Pandas
Pandas является ключевым инструментом для анализа данных в Python, но не всегда удается сделать данные презентабельными. Из-за этого многие аналитики по-прежнему обращаются к Excel для добавления стилей данных (например, валют) или условного форматирования перед тем, как делиться данными с более широкой аудиторией. В этом посте мы рассмотрим, как взять эти распространенные в Excel функции и показать, как их использовать с помощью API стилей Pandas!
Зачем нам стилизовать данные? Наша конечная цель должна состоять в том, чтобы сделать данные более понятными для наших читателей, сохраняя при этом удобство использования базовых данных, доступных в кадре данных. Например, 10% может быть легче понять, чем значение 0,10, но доля 0,10 более пригодна для дальнейшего анализа.
**Оглавление**
* [Что такое API стиля Pandas?](#chto-takoe-api-stilya-pandas)
* [Загрузка нашего образца набора данных](#zagruzka-nashego-obrazca-nabora-dannykh)
* [Метки типов данных для Pandas](#metki-tipov-dannykh-dlya-pandas)
* [Добавление условного форматирования](#conditional-formatting-pandas)
* [Добавление цветовых шкал в Pandas](#dobavlenie-cvetovykh-shkal-v-pandas)
* [Ограничение столбцов для форматирования](#ogranichenie-stolbcov-dlya-formatirovaniya)
* [Добавление цветных полос в Pandas](#dobavlenie-cvetnykh-polos-v-pandas)
* [Как повторно использовать стили в Pandas](#kak-povtorno-ispolzovat-stili-v-pandas)
* [Скрытие индекса или столбцов](#skrytie-indeksa-ili-stolbcov)
* [Экспорт стилизованных фреймов данных в Excel](#eksport-stilizovannykh-freimov-dannykh-v-excel)
* [Может быть, просто использовать Excel?](#mozhet-byt-prosto-ispolzovat-excel)
* [Заключение: изучение API стиля Pandas](#zaklyuchenie-izuchenie-api-stilya-pandas)
### Что такое API стиля Pandas?
Pandas разработал API стилизации в 2019 году, и с тех пор оно активно развивается. API возвращает новый объект **Styler**, который имеет полезные методы для применения форматирования и стилизации к фреймам данных. Итоговое оформление достигается с помощью CSS, посредством функций стиля, которые применяются к скалярам, сериям или целым фреймам данных, через пары
Объекты **Styler** имеют два ключевых метода:
1. **Styler.applymap** — применяет стили к каждому элементу отдельно
2. **Styler.apply** – применяет стили по столбцам/строкам/фреймам данных.
Давайте начнем с загрузки наших данных.
### Загрузка нашего образца набора данных
Мы будем использовать тот же набор данных, что и в нашем руководстве по сводным таблицам, а также применим некоторые из шагов, описанных там. Если вы не знакомы с сводными таблицами в Pandas, мы рекомендуем ознакомиться с нашим учебником
{% hint style="info" %}
Возможно у Вас отсутствует необходимая зависимость ‘openpyxl’. Это библиотека, которая используется для чтения и записи файлов формата Excel (xlsx). Давайте установим ее.
{% endhint %}
```python
pip install openpyxl
```
```python
import pandas as pd
df = pd.read_excel('https://github.com/BeMindYou/Lesson/raw/main/Data/sample_pivot.xlsx', parse_dates=['Date'])
print(df.head())
```
```python
# Возвращает:
Date Region Type Units Sales
0 2020-07-11 East Children's Clothing 18 306
1 2020-09-23 North Children's Clothing 14 448
2 2020-04-02 South Women's Clothing 17 425
3 2020-02-28 East Children's Clothing 26 832
4 2020-03-19 West Women's Clothing 3 33
```
Мы видим, что у нас есть ряд продаж, предоставляющих информацию о Регионе, Типе, Количестве проданных единиц и общей Стоимости продаж.
Давайте создадим сводную таблицу, следуя нашему учебнику:
```python
pivot = pd.pivot_table(df, index = ['Region', 'Type'], values = 'Sales', aggfunc = 'sum')
print(pivot)
```
```python
Output:
Sales
Region Type
East Children's Clothing 45849
Men's Clothing 51685
Women's Clothing 70229
North Children's Clothing 37306
Men's Clothing 39975
Women's Clothing 61419
South Children's Clothing 18570
Men's Clothing 18542
Women's Clothing 22203
West Children's Clothing 20182
Men's Clothing 19077
Women's Clothing 22217
```
Теперь, когда наши данные загружены и сохранены в датафрейм с именем ***pivot***, мы можем начать стилизацию наших данных в Pandas.
### Метки типов данных для Pandas
В нашем датафрейме ***pivot***, столбцы **Sales** показывают общее количество продаж в долларах. Однако это сразу не очевидно для читателя, так как нет символа доллара, а тысячные значения не разделены запятыми. Давайте рассмотрим, как это можно исправить:
```python
pivot.style.format({'Sales':'${0:,.0f}'})
```
```python
Output:
Sales
Region Type
East Children's Clothing $45,849
Men's Clothing $51,685
Women's Clothing $70,229
North Children's Clothing $37,306
Men's Clothing $39,975
Women's Clothing $61,419
South Children's Clothing $18,570
Men's Clothing $18,542
Women's Clothing $22,203
West Children's Clothing $20,182
Men's Clothing $19,077
Women's Clothing $22,217
```
Мы можем видеть, что данные становятся сразу легче для понимания!
Строковые форматы можно применять по-разному. Некоторые другие примеры включают в себя:
* Плавающее значение с 2 десятичными знаками: `{:.2f}`
* Дополнить числа нулями: `{:0>2d}`
* Процент с 2 знаками после запятой: `{:.2f%}`
Чтобы узнать больше, ознакомьтесь с этим отличным учебником от [Real Python](https://realpython.com/python-formatted-output/)
Если бы мы хотели передать форматирование для нескольких столбцов, то создание словаря, который можно передать функции стилизации, могло бы быть более удобным способом. Например, мы могли бы написать словарь, как показано ниже:
```python
format_dictionary = {
'column1':'format1',
'column2':'format2'
}
```
Который затем может быть передан объекту, как показано ниже:
```python
pivot.style.format(format_dictionary)
```
### Добавление условного форматирования
Условное форматирование - отличный инструмент, легко доступный в Excel. Он позволяет нам легко идентифицировать значения на основе их содержания. В Pandas это так же просто, но немного скрыто. Мы покажем, насколько просто достичь условного форматирования в Pandas.
Например, если мы хотим выделить любое количество продаж, превышающих 50 000 долларов (скажем, они имеют право на бонус после этой точки). Мы можем сделать это с помощью метода applymap. Прежде чем мы начнем, мы определим функцию, которую можем передать методу applymap.
```python
def highlight_fifty(val):
color = 'red' if val > 50000 else 'black'
return 'color: %s' % color
```
Мы теперь можем передать эту функцию в метод applymap:
```python
pivot_highlight = pivot.style.applymap(highlight_fifty)
pivot_highlight
```
Это приводит к следующему датафрейму:
Мы также можем сочетать стилизацию данных с нашим условным форматированием:
```python
pivot_highlight = pivot.style.applymap(highlight_fifty).format({'Sales':'${0:,.0f}'})
pivot_highlight
```
#### Упрощение чтения цепных методов
Цепочка методов - это невероятно полезная функция в Python, но не всегда легко читаемая. Мы можем разделить цепочку на несколько строк, используя символ , как показано ниже:
```python
pivot_highlight = pivot.style.format({'Sales':'${0:,.0f}'})\
.highlight_max(color='green')\
.highlight_min(color='red')
pivot_highlight
```
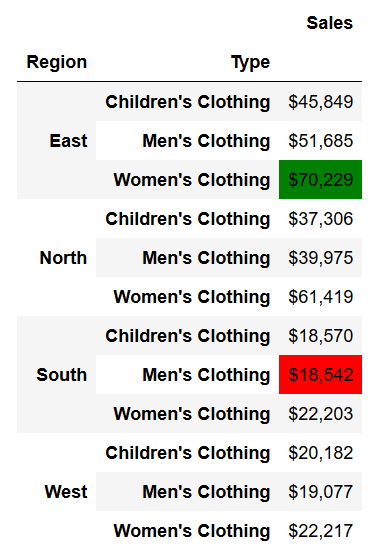
Теперь, если мы хотим выделить максимальные и минимальные значения, мы можем достичь этого с помощью другого объекта Styler. Хотя мы могли бы сделать это, используя функции и метод applymap, к счастью, в Pandas уже есть встроенные методы для выделения максимальных и минимальных значений. В приведенном ниже примере мы используем именованные цвета, но вы также можете указать значения в формате hex, чтобы быть более конкретными.
```python
pivot.style.format({'Sales':'${0:,.0f}'}) \
.highlight_max(color='green') \
.highlight_min(color='red')
```
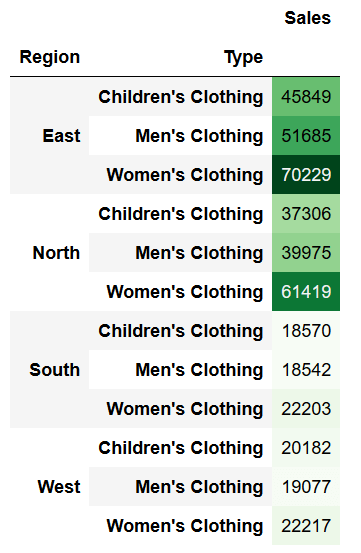
### Добавление цветовых шкал в Pandas
Иногда нам может понадобиться определить значения внутри столбца относительно друг друга. Здесь на помощь приходят цветовые шкалы. Используя метод `background_gradient`, мы можем с легкостью реализовать это как стиль. Давайте попробуем это сделать.
```python
pivot.style.background_gradient(cmap='Greens')
```
Перевести на русский
Вы также можете использовать различные цветовые карты (cmaps). Чтобы узнать больше о цветовых картах, ознакомьтесь с [этим руководством по Matplotlib](https://matplotlib.org/tutorials/colors/colormaps.html).
### Ограничение столбцов для форматирования
Давайте теперь создадим сводную таблицу с несколькими столбцами значений:
```python
pivot2 = pd.pivot_table(df, index = ['Region', 'Type'], values = 'Sales', aggfunc = ['sum','count'])
```
В результате создается сводная таблица, которая выглядит следующим образом:
```python
sum count
Sales Sales
Region Type
East Children's Clothing 45849 113
Men's Clothing 51685 122
Women's Clothing 70229 176
North Children's Clothing 37306 85
Men's Clothing 39975 89
Women's Clothing 61419 142
South Children's Clothing 18570 45
Men's Clothing 18542 39
Women's Clothing 22203 53
West Children's Clothing 20182 42
Men's Clothing 19077 41
Women's Clothing 22217 53
```
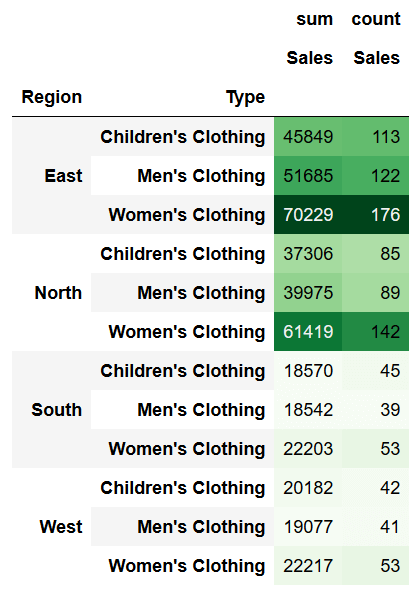
Теперь давайте применим метод `.background_gradient`
```python
pivot2.style.background_gradient(cmap='Greens')
```
Это возвращает следующий кадр данных:
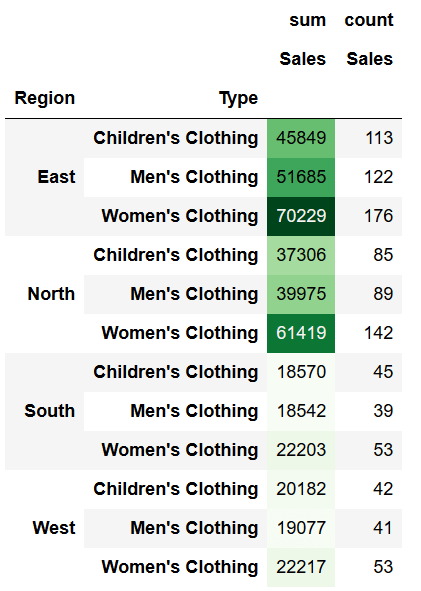
Если мы хотим ограничить это только одним столбцом, мы можем использовать параметр subset, как показано ниже:
```python
pivot2.style.background_gradient(subset=['sum'], cmap='Greens')
```
### Добавление цветных полос в Pandas
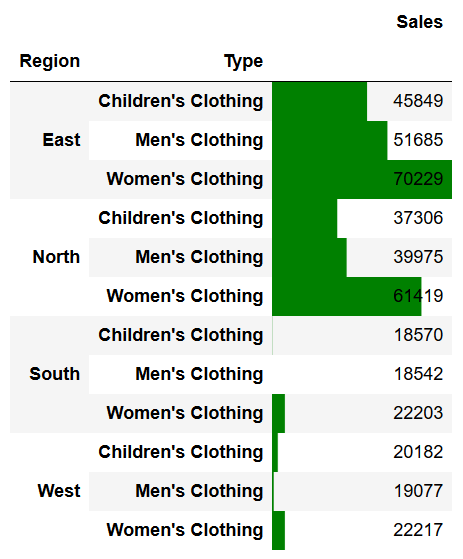
Еще один наглядный способ добавить контекст к размеру значения в колонке - это добавить цветные полосы. Это невероятно простой способ предоставить визуализацию, которая также легко печатается. Мы можем достичь этого, используя Python и следующий код:
```python
pivot.style.format({'Sales':'${0:,.0f}'}).bar(color='Green')
```
Это возвращает следующий кадр данных:
Цветные полосы позволяют нам легче видеть шкалу. Также мы можем использовать параметр *`align`*`=center`, чтобы отображать полосы слева, если значения отрицательные, и справа, если положительные.
### Как повторно использовать стили в Pandas
После того, как вы провели некоторое время, создавая стиль, который вам действительно нравится, вы можете захотеть использовать его снова. К счастью, Pandas упрощает эту задачу, и вам не придется дублировать код, который вы создали с таким трудом. Для этого можно использовать метод `.use` на объекте Style другого датафрейма. Например, если у нас есть два датафрейма, style1 и style2, мы можем повторно использовать стиль style1, используя следующий код:
```python
style1.style.format({'Sales':'${0:,.0f}'}).bar(color='Green')
style2.use(style1.export())
```
### Скрытие индекса или столбцов
Поскольку мы говорим о подготовке данных к отображению, давайте также поговорим о другом аспекте, который Excel упрощает для нас: скрытие столбцов. В Pandas это также можно сделать с помощью объектов стиля. Если бы нам нужно было скрыть индекс, мы могли бы написать:
```python
df.head().style.hide_index()
```
```python
Date Region Type Units Sales
2020-07-11 00:00:00 East Children's Clothing 18.000000 306
2020-09-23 00:00:00 North Children's Clothing 14.000000 448
2020-04-02 00:00:00 South Women's Clothing 17.000000 425
2020-02-28 00:00:00 East Children's Clothing 26.000000 832
2020-03-19 00:00:00 West Women's Clothing 3.000000 33
```
Аналогично, если мы хотим скрыть столбец, мы можем написать:
```python
df.head().style.hide_columns(['Units'])
```
```python
Date Region Type Sales
0 2020-07-11 00:00:00 East Children's Clothing 306
1 2020-09-23 00:00:00 North Children's Clothing 448
2 2020-04-02 00:00:00 South Women's Clothing 425
3 2020-02-28 00:00:00 East Children's Clothing 832
4 2020-03-19 00:00:00 West Women's Clothing 33
```
### Экспорт стилизованных фреймов данных в Excel
В начале статьи я упоминал, что API стилей в Pandas все еще находится в стадии эксперимента. В настоящее время мы не можем экспортировать все эти методы, но можем экспортировать *фоновый цвет* и *цвет*. Например, если бы мы хотели экспортировать следующий dataframe:
```python
pivot.style.bar(color='Green')
```
Мы можем использовать метод `.to_excel` для экспорта нашего стилизованного датафрейма в Excel-рабочую книгу:
```python
pivot.style.background_gradient(cmap='Greens').to_excel('Styled_Dataframe.xlsx', engine='openpyxl')
```
### Может быть, просто использовать Excel?
В некоторых случаях может оказаться более эффективным просто перенести ваши данные в Excel. В этом случае вы можете использовать метод `df.to_clipboard()` для копирования всего датафрейма в буфер обмена!
```python
df.to_clipboard()
```
### Заключение: изучение API стиля Pandas
В этом посте мы научились стилизовать датафреймы Pandas с помощью Style API Pandas. Мы узнали, как добавлять стили типов данных, условное форматирование, цветовые гаммы и цветные полосы. Похоже на стили, найденные в Excel, Pandas упрощает применение стилей к датафреймам. Это позволяет нам лучше представлять данные и визуально находить тенденции в данных.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://bemind.gitbook.io/neural/uchebniki-po-pandas-i-numpy/pandas/izuchenie-api-stilya-pandas.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.