
Диаграммы рассеяния Matplotlib – Все, что вам нужно знать
Загружаем наши данные
df = pd.read_csv("https://github.com/fivethirtyeight/WNBA-stats/raw/master/wnba-player-stats.csv",
usecols = ['player_ID', 'Age', 'MP', 'Tm', 'Wins_Generated', 'year_ID', 'Composite_Rating']
)
df = df[df['Tm'].isin(['ATL', 'CHI'])]
df = df.rename(columns={
'player_ID': 'ID',
'MP':'Minutes',
'Tm':'Team',
'Wins_Generated': 'Wins',
'year_ID':'Year'
})
df['Team'] = df['Team'].str.replace('ATL', 'Atlanta')
df['Team'] = df['Team'].str.replace('CHI', 'Chicago')
print(df.head()) ID Year Age Team Minutes Composite_Rating Wins
0 montgre01w 2019 32 Atlanta 949 -2.4 1.22
1 williel01w 2019 26 Atlanta 909 0.6 2.51
2 sykesbr01w 2019 25 Atlanta 880 -3.4 0.70
3 hayesti01w 2019 29 Atlanta 817 -1.5 1.45
4 brelaje01w 2019 31 Atlanta 767 -0.8 1.62Как создать диаграммы рассеяния Matplotlib?
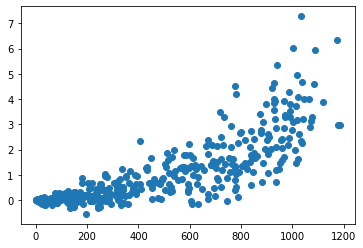
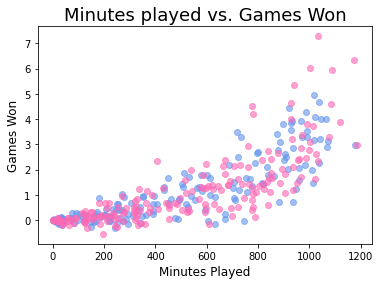
Как добавить заголовки и метки осей в диаграммы рассеяния Matplotlib?
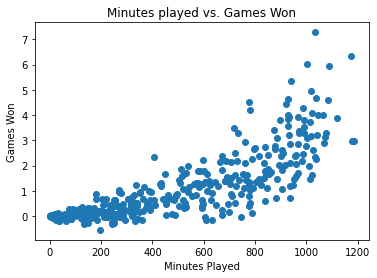
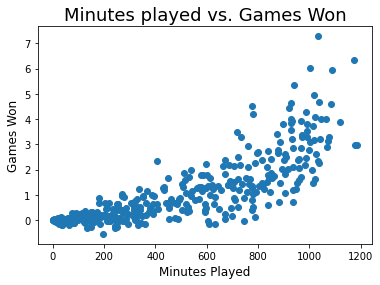
Как настроить цвета разбросанных маркеров?
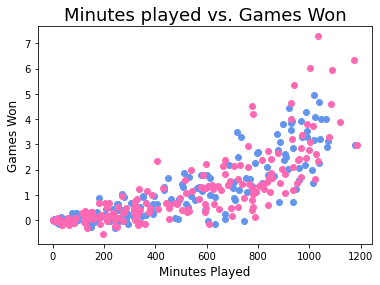
Как изменить прозрачность маркера?
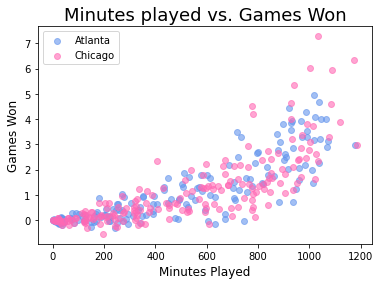
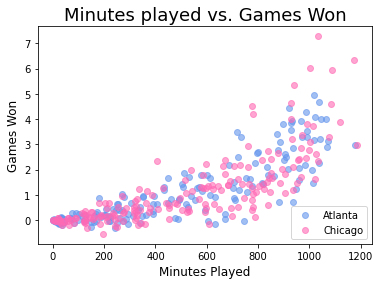
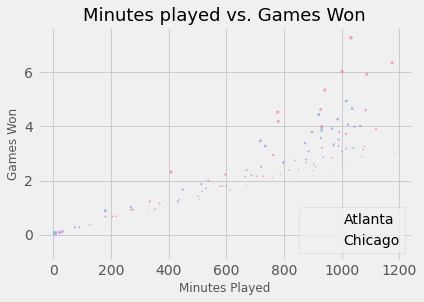
Как добавить легенду в диаграммы рассеяния Matplotlib?
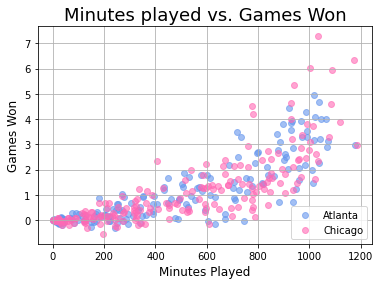
Как добавить сетку на диаграммы?
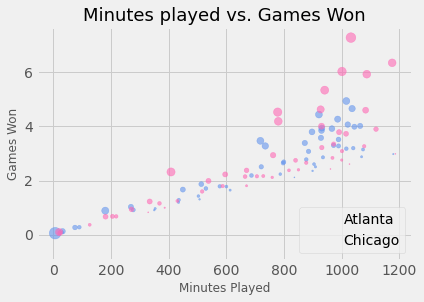
Как изменить размер маркера в диаграммах рассеяния Matplotlib?
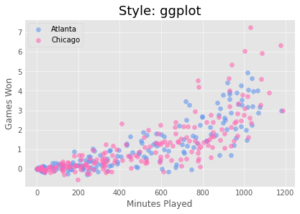
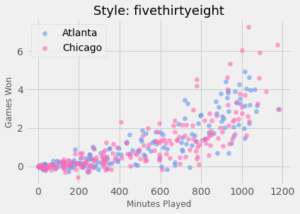
Как добавить стиль к диаграммам Matplotlib?
Заключение
ПредыдущаяПостроение графиков в Python с помощью MatplotlibСледующаяДиаграммы с столбцами в Matplotlib – Узнайте все, что вам нужно знать
Последнее обновление