
Seaborn kdeplot – Создание графиков оценки плотности ядра
В этом руководстве вы научитесь использовать функцию histplot() библиотеки Seaborn для создания гистограмм, которые визуализируют распределение набора данных. Гистограммы являются ценными инструментами для визуализации распределения наборов данных, позволяя вам глубже понять ваши данные. В этом учебном пособии вы узнаете о различных параметрах и опциях функции histplot библиотеки Seaborn.
К концу этого урока вы узнаете следующее:
Как работает функция Seaborn
kdeplot()Как настроить графики Seaborn KDE, используя цвет, сглаживание и различные интервалы
Как визуализировать две непрерывные переменные с помощью функции Seaborn kdeplot
Оглавление
Понимание функции Seaborn kdeplot
Перед тем как приступить к созданию графиков плотности ядра в Seaborn, давайте рассмотрим функцию sns.kdeplot() и ее параметры. Как показывает приведенный ниже блок кода, функция предлагает большое количество параметров, а также аргументы по умолчанию.
Не волнуйтесь - вам не нужно будет знать все эти параметры. Фактически, мы даже не будем рассматривать все эти параметры в рамках этого руководства. Однако мы исследуем самые важные из них, включая следующие ниже:
data=предоставляет данные для построения графика через Pandas DataFramex=иy=предоставляют переменные для отображения на осях x и y соответственноhue=добавляет дополнительную переменную к графику через цветовое сопоставлениеmultiple=указывает, как обрабатывать сопоставление нескольких переменных, включая суммирование или создание 100%-ных диапазонов.
Теперь, когда у вас есть хорошее понимание некоторых наиболее важных параметров, давайте перейдем к созданию графиков KDE в Seaborn.
Создание графика Seaborn KDE с помощью kdeplot
Для создания оценки плотности распределения (kernel density estimate) с помощью Seaborn, вам нужно лишь предоставить DataFrame через аргумент data= и указать название колонки через аргумент x=. После этого Seaborn автоматически создаст оценку плотности распределения и отобразит её на графике. Давайте посмотрим, как это выглядит:
В кодовом блоке выше мы указали Seaborn построить KDE график для колонки 'bill_depth_mm' нашего DataFrame. Это приводит к изображению ниже, представляющему оценочную функцию:

Хотя функция и не отражает реальное распределение данных, она пытается создать оценку того, как функция могла бы выглядеть.
Создание горизонтального графика KDE в Seaborn
В приведенном выше примере наш KDE график был нарисован вертикально. Seaborn также позволяет создать горизонтальный график оценки плотности ядра, просто поместив столбец, который вы хотите построить, в параметр y=, вместо параметра x=
Давайте посмотрим, как можно создать горизонтальный график KDE в Seaborn:
Изменяя параметр на y=, Seaborn создает тот же график, что и в предыдущем разделе, и отображает его горизонтально.

По умолчанию Seaborn использует автоматическое масштабирование для создания гладкой кривой. В следующем разделе вы научитесь настраивать сглаживание.
Изменение ширины интервала в графиках Seaborn KDE
Seaborn позволяет настраивать сглаживание (или ширину бина) для оценки плотности распределения с помощью параметра bw_adjust=. Чем больше значение, тем гладче кривая. Мы можем добавить больше деталей к кривой, уменьшив значение.
В приведенном выше блоке кода мы использовали параметр bw_adjust=0.3. Это уменьшает сглаживание и добавляет больше деталей в колебания базовой функции, как показано ниже:

Давайте теперь исследуем, как мы можем создавать графики, которые не выходят за пределы крайних значений.
Предотвращение расширения прошлых экстремальных точек на графиках Seaborn KDE
Для создания сглаженной линии Seaborn может потребоваться расширить график функции за пределы крайних точек. Этот коэффициент умножается на ширину сглаживания. Однако мы можем обрезать кривую по границам данных, установив параметр cut= равным 0.
Давайте посмотрим, как это выглядит на Python:
В приведенном выше примере мы добавили к нашей функции параметр cut=0. Это привело к обрезке функции на крайних точках (то есть они резко заканчиваются вдоль оси x). Это может гарантировать, что будет меньше предположений относительно распределения базовых данных.

В следующем разделе вы научитесь добавлять дополнительные детали к KDE графикам с использованием цвета.
Добавление цветов в графики Seaborn KDE
До сих пор мы создавали графики плотности распределения Seaborn, которые отображают одну оценку. Однако мы можем добавить дополнительные детали, используя цветовую семантику, применив параметр hue=. Мы можем передать дополнительный столбец DataFrame Pandas в параметр hue=
В указанном выше блоке кода мы добавили колонку 'species' в параметр hue=. Поскольку эта колонка содержит три уникальных значения, Seaborn нарисует три отдельные линии, как показано ниже:

Данные представлены в виде отдельных функций. Хотя мы можем видеть отдельные оценки, может быть сложнее увидеть детали всего распределения. В следующем разделе вы узнаете, как решить эту проблему.
Объединение данных с цветом на графиках Seaborn KDE
В предыдущем разделе вы научились строить отдельные оценки плотности ядра для распределения, разделенного по другому столбцу. Вы можете сложить отдельные распределения, чтобы предоставить детали о каждой категории, одновременно представляя распределение в целом
Для этого вы можете передать multiple='stack', что позволит складывать отдельные оценки друг на друга. Давайте посмотрим, как это выглядит:
В указанном выше блоке кода мы указали, что хотим, чтобы несколько перекрывающихся категорий накладывались друг на друга. Это позволяет лучше понять общее распределение данных, одновременно предоставляя информацию о дополнительных категориях.

Мы можем пойти еще дальше, наложив цвета друг на друга в диаграмме до 100%, о чем вы узнаете в следующем разделе.
Увеличение цвета до 100% в графиках Seaborn KDE
Seaborn позволяет даже накладывать оценку плотности до 100%. Это дает вам четкое представление о том, как каждая категория представлена в каждой точке распределения. Для этого можно использовать multiple='fill', что заполнит весь график.
Давайте посмотрим, как это выглядит на Python:
При изменении параметра multiple= на 'fill', вся высота графика используется. Это позволяет увидеть, насколько каждый элемент представлен в распределении.

До сих пор мы добавляли к нашему графику плотности распределения категориальную переменную, используя семантику цвета, однако мы также можем использовать непрерывные переменные.
Построение непрерывных переменных в виде графика KDE в Seaborn
Seaborn также упрощает добавление непрерывной переменной к семантике hue=, что означает, что каждое значение будет представлено шкалой цветов.
Это позволяет вам использовать цвет, чтобы видеть, как переменная изменяется по шкале. Давайте посмотрим, как это выглядит на примере другого набора данных:
В приведенном выше блоке кода мы изменили одну из переменных на целое число, чтобы наша визуализация выглядела чище. Затем мы передали эту переменную в параметр hue=. По мере увеличения значения 'x', цвет становится темнее.

Теперь давайте углубимся в то, как изменить дополнительные параметры функции Seaborn kdeplot, научившись создавать накопительные графики.
Расчет совокупных графиков KDE в Seaborn
Seaborn упрощает построение кумулятивного графика оценки плотности ядра, используя параметр cumulative=. Создание кумулятивного графика позволяет вам увидеть, какие значения представлены в распределении, что означает возможность лучше понять тенденции в данных.
Давайте посмотрим, как мы можем изменить параметр cumulative=, чтобы создать накопительный график KDE:
При использовании параметра cumulative=True, можно создать накопительный график плотности распределения (KDE), как показано ниже:

Мы можем расширить это еще дальше, используя аргумент hue=. Чтобы значения каждого распределились до 100%, нам также потребуется установить common_norm=False. Без этого значения будут распределяться только до общего их распределения.
В приведенном выше блоке кода мы попросили Seaborn создать кумулятивные графики KDE, разделенные по цветам, что привело к следующей визуализации:
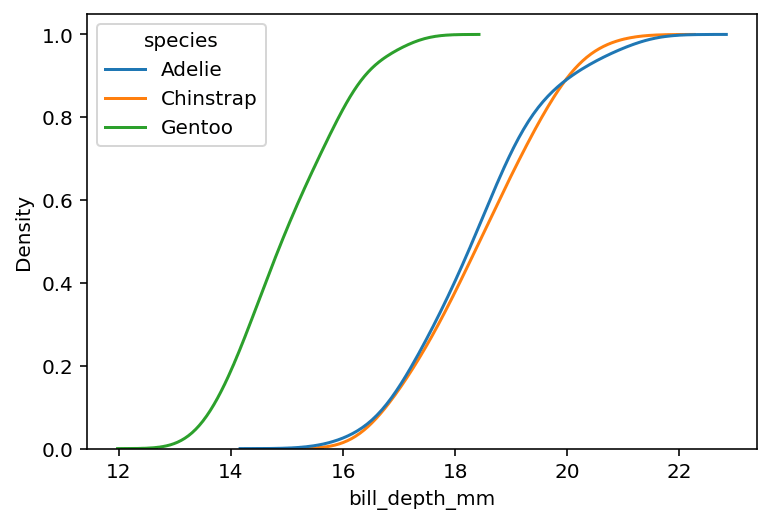
В следующем разделе мы рассмотрим, как использовать логарифмическую шкалу в kdeplot библиотеки Seaborn.
Использование логарифмической шкалы на графике Seaborn KDE
При работе с большими объемами данных может быть полезно отображать данные, используя логарифмическую шкалу. Чтобы создать плотность распределения вероятности в Seaborn с использованием логарифмической шкалы, вы можете указать log_scale=True. По умолчанию этот параметр установлен в значение False, что означает, что данные отображаются без использования логарифмической шкалы.
Давайте посмотрим, как мы можем это сделать, используя набор данных 'diamonds', который включен в Seaborn:
Запустите приведенный выше код без использования аргумента log_scale=True и посмотрите, как визуализация отличается от показанной ниже. Когда это уместно, логарифмические шкалы могут помочь вам лучше понять распределение набора данных.

Давайте теперь погрузимся в то, как построить бивариативное распределение, используя сглаженные гистограммы Seaborn.
Построение двумерных распределений на графиках Seaborn KDE
Чтобы построить двумерную оценку плотности ядра в Seaborn, вы можете передать две переменные в параметры x= и y= соответственно. Это покажет, как две переменные взаимодействуют друг с другом, исходя из данных в распределении.
Давайте посмотрим, как мы можем это сделать на Python, передав две переменные:
Это возвращает следующую визуализацию, которую можно интерпретировать как карту высот.

Мы можем дополнительно расширить этот график, используя семантику цвета с помощью параметра hue=
Построение двумерных распределений в графиках Seaborn KDE с цветом
На графике, который мы создали в предыдущем разделе, легко заметить, что в наших данных существуют различные кластеры. Исследовать эти кластеры можно с помощью семантического параметра hue=, который позволяет отображать дополнительную переменную с использованием цвета.
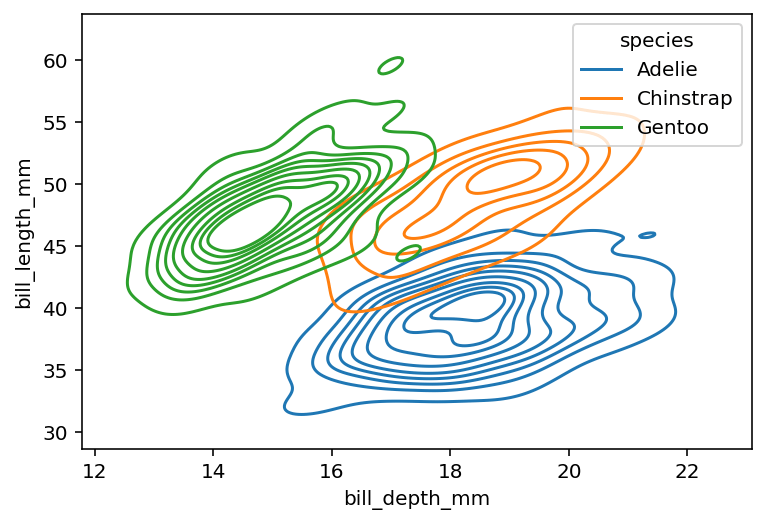
Давайте посмотрим, как мы можем добавить цвет в наш двумерный график плотности ядра (KDE):
Взгляните на приведенную ниже диаграмму! Вы можете видеть, что три кластера коррелируют с нашими разными видами в этом распределении.
It can still be difficult to see where data are clustered. Because of this, we can fill our bivariate KDE plot to see where data are clustered by passing in fill=True.
Иногда может быть сложно увидеть, где данные сгруппированы. Поэтому мы можем использовать заливку нашего двухмерного графика плотности распределения, чтобы лучше увидеть группировку данных, используя параметр fill=True.
Лично я считаю это наиболее интуитивно понятным для понимания бивариатных графиков плотности ядра при добавлении цветовой семантики.
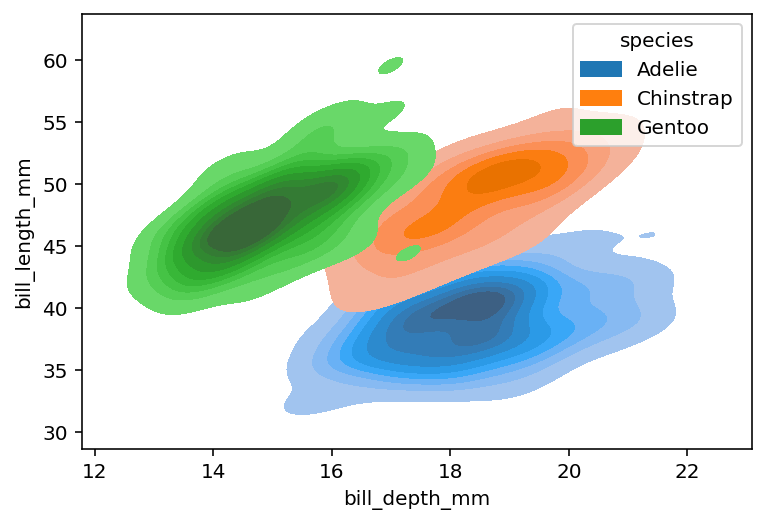
Одна вещь, которую нужно помнить, это то, что некоторые данные теперь скрыты.
Заключение
В этом руководстве вы узнали, как использовать функцию kdeplot() в Seaborn для создания информативных графиков оценки плотности ядра в Seaborn. Графики KDE позволяют вам глубже понять распределение данных.
Впервые вы узнали, что предлагает функция Seaborn kdeplot с точки зрения параметров и аргументов по умолчанию. Затем вы научились создавать простые графики KDE. Далее вы использовали полученные знания для создания более сложных и информативных графиков KDE, добавляя цвета, изменяя масштабы и т. д. Наконец, вы научились создавать двумерные графики KDE.
Дополнительные ресурсы
Чтобы узнать больше о связанных темах, посетите ресурсы ниже:
Последнее обновление