
Дисперсия в Pandas: Вычисление дисперсии столбца в Pandas Dataframe
# Вычисление дисперсии Pandas для одного столбца
import pandas as pd
df = pd.DataFrame({
'name': ['James', 'Jane', 'Melissa', 'Ed', 'Neil'],
'ages': [30, 40, 32, 67, 43],
'ages_missing_data': [30, 40, 32, 67, None],
'income': [100000, 80000, 55000, 62000, 120000]
})
variance = df['income'].var()
print(variance)
# Возвращает: 722800000.0Что такое статистика дисперсии?
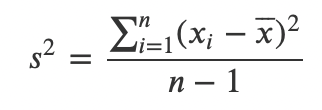
Как рассчитать дисперсию в Python
Загрузка образца Pandas Dataframe
Как рассчитать дисперсию в Pandas для одного столбца
Как работать с пропущенными данными при расчете дисперсии Pandas
Как рассчитать дисперсию в Pandas для нескольких столбцов
Как рассчитать дисперсию в Pandas для Dataframe
Заключение
ПредыдущаяPandas: Преобразование значений столбца в строкиСледующаяPandas: Создание DataFrame из списков (5 способов!)
Последнее обновление