
Индексация, Выборка и Присваивание Данных в Pandas
В этом руководстве вы узнаете, как индексировать, выбирать и присваивать данные в DataFrame Pandas. Понимание того, как индексировать и выбирать данные, является важным первым шагом в почти любом исследовании данных, которое вы предпримете в области науки о данных. Подобно этому, знание того, как присваивать значения в Pandas, может открыть целый мир возможностей при работе с DataFrame.
Содержание
Загрузка образца фрейма данных Pandas
Чтобы начать, давайте снова загрузим наш DataFrame pandas. Мы используем DataFrame, который содержит примеры информации о продажах в различных регионах за год. Набор данных размещен на странице Github datagy, и его можно загрузить непосредственно в pandas DataFrame. Давайте создадим DataFrame с именем df, который будет содержать все наши данные:
# Загрузка нашего DataFrame Pandas
df = pd.read_csv('https://raw.githubusercontent.com/AlexBugalter/Lesson/main/sales.csv')Два типа индексов DataFrame
DataFrame в pandas можно рассматривать как множество объектов Series, собранных вместе. Объект Series в pandas уже имеет индекс, который в случае DataFrame pandas представляет собой значение строки. Однако DataFrame также имеет индекс столбцов, который представлен позицией столбца. Из-за этого DataFrame pandas фактически имеет два индекса!
Мы различаем эти индексы по их оси. Индекс, который идет вдоль оси 0, является индексом строки, в то время как индекс, который идет вдоль оси 1, является индексом столбца. Пересечение этих двух индексов представлено определенным значением.
Это может показаться немного запутанным и, возможно, даже немного ненужным. Однако это открывает множество возможностей! Это позволяет, например, получать доступ к значениям не только по их позиции, но и по меткам. Это может быть очень полезно, когда нужно извлечь конкретное значение, не зная, где именно оно находится, но зная, что оно существует.
Доступ к столбцам в DataFrame Pandas
Есть два основных способа доступа ко всем столбцам в Pandas:
Используя
.(точечную) нотацию, илиИспользование
[]индексации с квадратными скобками
Давайте посмотрим, как можно получить доступ к определённому столбцу в нашем DataFrame pandas с помощью метода точечной нотации:
Интересно, что при выборе столбца DataFrame в pandas он фактически возвращает объект Series! Мы можем подтвердить это, передав столбец в качестве аргумента функции type()
Аналогично, мы можем получить доступ к столбцу gender с помощью квадратных скобок:
Под капотом оба этих метода работают совершенно одинаково. Так почему выбрать один из них? Метод индексирования с помощью квадратных скобок позволяет нам как выбирать столбцы, которые используют зарезервированные слова, так и выбирать столбцы, в которых есть пробелы. Мой личный выбор - это метод квадратных скобок, так как он работает без ошибок. Хотя кажется, что на его написание уходит больше времени, он обеспечивает постоянно корректные результаты!
Еще одно преимущество использования метода квадратных скобок для выбора столбцов заключается в том, что мы можем выбирать несколько столбцов! Мы можем поместить нужные столбцы в список и передать его. Например, чтобы выбрать столбцы gender и region, мы можем написать следующий код:
Есть несколько вещей, которые стоит отметить:
Нам нужно обернуть наш выбор в то, что выглядит как двойные квадратные скобки
Это фактически возвращает DataFrame Pandas, а не Series
Теперь, когда у вас есть понимание того, как выбирать столбцы в Pandas, давайте перейдем к выбору строк – о чем вы узнаете в следующем разделе.
Доступ к строкам в DataFrame Pandas
Доступ к строкам в Pandas немного отличается от доступа к столбцам, но это тоже очень интуитивно. Нам нужно рассмотреть немного теории перед тем, как учиться доступу к строкам. Это потому, что доступ к строкам работает в сочетании с выбором столбцов.
Прежде чем перейти к выбору строк, давайте рассмотрим два типа аксессоров, доступных в pandas: .loc[] и .iloc[]. Начнем с оператора .loc[], который известен как выбор на основе меток. С его помощью мы можем получать доступ к столбцам, строкам и значениям по их меткам!
Использование loc для выбора строк в Pandas DataFrame
Изображение ниже показывает, как выбрать данные с помощью оператора .loc. Оператор разделен на два атрибута, разделенных запятыми. В первую часть мы помещаем выбор строк, а во вторую выбор
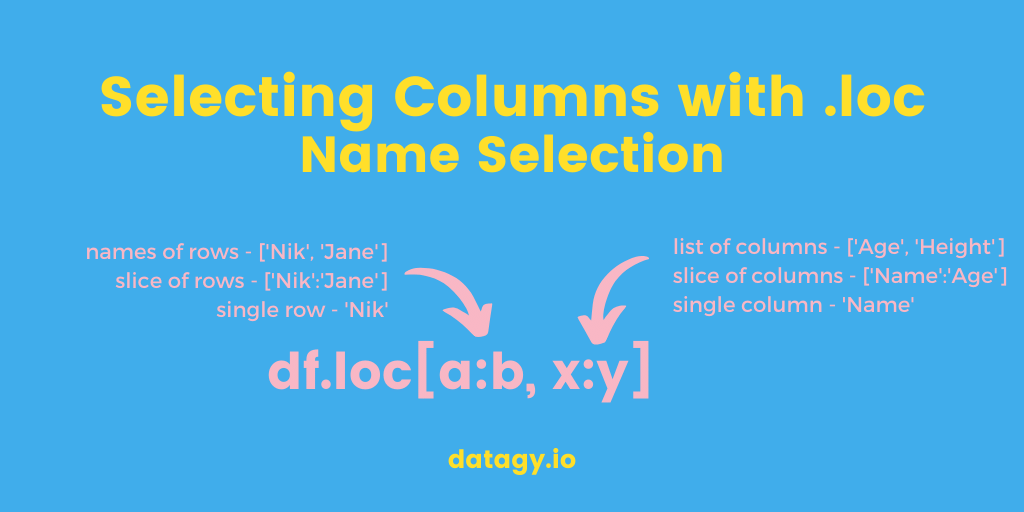
Это работает очень похоже на индексирование списков в Python, где мы можем использовать двоеточие (:), чтобы указать выбор всего списка. Это означает, что мы можем извлечь определенную строку, выбрав её индекс строки и просто выбрав все столбцы!
Давайте посмотрим, как мы можем получить доступ к первой строке с помощью оператора .loc
Здесь мы обращаемся к строке по ее метке: 0. Это метка, которая назначена в индексе. Pandas по умолчанию присваивает индексы от 0 до конца DataFrame. В данном случае 0 относится как к метке, так и к позиции.
Хотите упростить это еще больше?
Поскольку мы на самом деле просто обращаемся к строке (и всем её столбцам), мы можем полностью опустить запятую и двоеточие. Запись df.loc[0] вернёт точно то же самое!
Использование iloc для выбора строк в кадре данных Pandas
Теперь давайте посмотрим, как можно выбрать строку (или строки) с использованием их позиций. Это можно сделать с помощью оператора .iloc. Оператор следует той же схеме сначала идентификации строк, а затем колонок. Ниже показано, как выбрать данные с помощью оператора .iloc:

Итак, если мы хотим получить доступ к первой строке, мы можем просто обратиться к нулевой строке и всем столбцам.
Помните, хотя этот метод выглядит так же, как оператор .loc, здесь мы обращаемся к 0-й позиции, тогда как ранее мы обращались к метке "0".
Теперь попробуйте написать строку кода, которая получит доступ к третьей-пятой строкам. Нажмите на этот раздел, чтобы увидеть решение.
Любое из решений ниже подойдет:
В следующем разделе вы узнаете, как выбирать конкретные значения в DataFrame pandas.
Доступ к значениям в DataFrame Pandas
Теперь, когда вы знаете, как выбирать строки и столбцы в pandas, мы можем использовать это для выбора конкретных данных. Мы можем сделать это с помощью .loc или .iloc в зависимости от того, что лучше подходит для наших нужд.
Поскольку мы не всегда знаем положение наших столбцов, имеет смысл начать с аксессора .loc. Предположим, мы хотим выбрать строку с меткой "0" и столбец "sales", мы могли бы написать следующий код:
Если мы хотим получить значение из последней строки в столбце 'sales', нам нужно использовать аксессор .iloc, чтобы можно было легко применить отрицательную индексацию. Напоминаем, что отрицательная индексация начинается с значения -1.
Теперь, когда вы знаете, как выбирать определенные значения на основе их меток и позиций, пора перейти к чему-то более сложному. В следующем разделе вы узнаете, как выбирать строки условно!
Выбор данных условно в Pandas DataFrame
Множество интересных манипуляций с данными требует условного подхода. В этом разделе вы узнаете, как выбрать данные условно. Допустим, мы хотим выбрать строки, где наши продажи принадлежат к региону Северо-Запад. Давайте рассмотрим, как выглядит это условие:
Давайте разберем, что здесь происходит:
Мы используем оператор
==для оценки условия.Тип данных (
dtype) возвращаемого рядаЭто возвращает булевую серию, которая оценивает, соответствует ли строка нашему условию или нет.
Вы можете думать, что эта серия не очень полезна. Однако, мы можем применить серию к нашему DataFrame для фильтрации строк! Чтобы это сделать, мы индексируем булеву серию. Давайте посмотрим, как это выглядит:
Это было легко! Мы можем даже комбинировать наши условия для дальнейшей их фильтрации, используя оператор & (и) или оператор | (или). Это соответствует обычным таблицам истинности Python. Скажем, мы хотим выбрать строки, где регион — 'North-West', и продажи превышают 15000. Для этого мы можем написать:
Обратите внимание, что для того, чтобы это сработало, нам нужно обернуть наши условия в обычные круглые скобки. В заключительном разделе этого урока вы узнаете, как назначать данные в DataFrame Pandas.
Назначение данных в Pandas
В этом финальном разделе вы узнаете, как начать назначать значения для DataFrame в Pandas. Поскольку это довольно обширная тема, вы узнаете только о нескольких методах назначении данных.
Назначение значения для целого столбца
Первый способ назначить значения в Pandas - это присвоить значение для целого столбца. Скажем, мы хотим добавить столбец, который описывает страну, и хотим установить значение 'USA' для каждой записи. Мы просто можем присвоить новое значение и передать строку:
Назначение значения конкретной ячейке
Мы также можем использовать .loc или .iloc для установки конкретного значения. Для этого сначала получаем нужную строку и столбец, а затем используем оператор присваивания, =, чтобы назначить значение. Предположим, мы хотим изменить значение пола первой записи на «Female». Мы могли бы сделать это, используя .iloc:
В этом примере мы обратились к первой записи и ко второй колонке, используя .iloc, а затем присвоили наше значение.
Упражнения
Чтобы закрепить знания, выполните следующие упражнения. Решения доступны, нажав на элемент ниже:
Заключение и резюме
В этом уроке вы узнали о выборе и присвоении данных в DataFrame Pandas. Оба этих навыка являются базовыми для работы с Pandas и могут потребовать обращения к справочным материалам по мере вашего продвижения. Ниже приведено краткое резюме того, что вы узнали:
DataFrame Pandas имеет два индекса: индекс строки и индекс столбца
Выбор одной колонки возвращает серию Pandas. Выбор нескольких колонок возвращает DataFrame.
Мы можем использовать аксессоры
.ilocдля доступа к данным по их позиции и аксессоры.locдля доступа к данным по их меткам.Мы можем выбирать данные условно, используя булевы серии и индексацию фрейма данных
Мы можем присваивать данные разными способами, в том числе используя аксессоры
.ilocи.loc
Дополнительные ресурсы
Чтобы узнать больше о смежных темах, ознакомьтесь со статьями, перечисленными ниже:
4 способа использовать Pandas для выбора столбцов в фрейме данных
Python: выберите случайный элемент из списка
7 способов выборки данных в Pandas
Python: разделить фрейм данных Pandas
Последнее обновление