
Pandas get_dummies (One-Hot кодирование), объяснение
Функция pd.get_dummies() из библиотеки Pandas позволяет легко выполнять one-hot кодирование категориальных данных. В этом руководстве вы узнаете, как работает функция get_dummies() в Pandas и как настраивать её поведение. One-hot кодирование — это распространённый этап предобработки данных при работе с категориальными переменными в машинном обучении.
Если вы планируете интегрировать one-hot кодирование в рабочий процесс с использованием scikit-learn, возможно, вам стоит рассмотреть класс OneHotEncoder из библиотеки scikit-learn!
К концу этого урока вы узнаете:
Что такое one-hot кодирование и зачем оно нужно
Как использовать функцию
pd.get_dummies()для one-hot кодирования данныхКак кодировать несколько столбцов с помощью
get_dummies()Как настраивать названия новых закодированных столбцов
Как обрабатывать пропущенные значения при использовании
get_dummies
Оглавление
Понимание one-hot кодирования в машинном обучении
One-hot кодирование — важный шаг подготовки данных для использования в алгоритмах машинного обучения. Оно преобразует категориальные данные в бинарное (нули и единицы) числовое представление, понятное моделям машинного обучения.
Это особенно важно при работе с такими алгоритмами, как деревья решений или машины опорных векторов (SVM), которые принимают только числовые входные данные.
Это работает следующим образом: для каждого уникального значения в категориальном столбце создаётся новый столбец. В этих новых столбцах значения равны 1, если значение исходного столбца совпадает с заголовком нового столбца, и 0 в противном случае.
См. изображение ниже для визуального представления процесса:
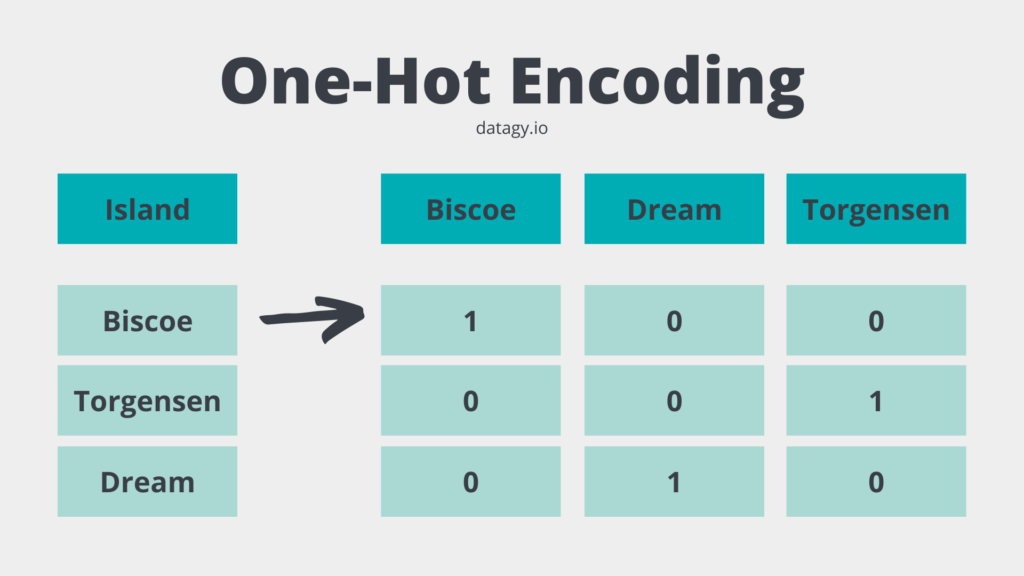
Вы можете спросить: почему бы просто не преобразовать значения в числа, например, присвоив {'Biscoe': 1, 'Torgensen': 2, 'Dream': 3}? Такой подход предполагает, что между значениями существует определённый порядок или числовая зависимость. Например, разница между Biscoe и Dream будет считаться большей, чем между Biscoe и Torgensen.
Хотя такая разница может существовать в некоторых случаях, в общем случае она не задана в данных и не должна учитываться автоматически.
Однако, если ваши данные порядковые (ordinal), то есть имеют чёткий порядок (например, размеры одежды: Small < Medium < Large), то такой способ кодирования может быть оправдан.
Какие недостатки у one-hot кодирования?
One-hot кодирование очень полезно при работе с категориальными переменными. Однако у него есть один серьёзный недостаток — оно значительно увеличивает количество данных. Для каждой уникальной категории создаётся новый столбец, что может привести к резкому росту размерности набора данных.
Из-за этого one-hot кодирование не рекомендуется использовать, если категорий слишком много (high cardinality).
Загрузка примера набора данных
Начнём урок с загрузки необходимых библиотек и создания тестового набора данных, который мы будем использовать на протяжении всего руководства. Если у вас уже есть собственный набор данных, вы можете пропустить этот шаг.
В приведённом выше коде мы загрузили DataFrame с тремя столбцами: Name, Gender и House Type. Столбцы Gender и House Type содержат категориальные данные. Теперь, когда у нас есть DataFrame, давайте перейдём к изучению функции pd.get_dummies().
Понимание функции Pandas get_dummies
get_dummiesПрежде чем переходить к использованию функции pd.get_dummies(), важно разобраться в её синтаксисе. Это поможет вам лучше понимать, какой результат вы получите, и как настроить работу функции под свои нужды.
Давайте посмотрим, из чего состоит функция pd.get_dummies():
Мы можем видеть, что функция предлагает большое количество параметров! Давайте разберём, за что отвечает каждый из них:
data=— данные, на основе которых создаются фиктивные переменные (может быть массивом, объектом Pandas Series или DataFrame)prefix=— строка, которую нужно добавить к названиям новых столбцовprefix_sep=— разделитель между префиксом и значением при формировании новых заголовковdummy_na=— добавлять ли отдельный столбец для пропущенных значений (NaN)columns=— список столбцов, которые нужно кодировать (если передан DataFrame)sparse=— использовать ли разрежённое представление данных (экономия памяти)drop_first=— удалять ли первый уровень (для предотвращения мультиколлинеарности)dtype=— тип данных для новых столбцов (например,int,floatи т. д.)
Теперь, когда вы хорошо понимаете параметры функции pd.get_dummies(), давайте рассмотрим, как использовать эту функцию для one-hot кодирования ваших данных.
Как использовать функцию pd.get_dummies() в Pandas
pd.get_dummies() в PandasВ предыдущем разделе вы узнали о доступных параметрах функции pd.get_dummies(). В этом разделе вы научитесь применять её для one-hot кодирования данных. Единственный обязательный параметр — это data=, который принимает либо объект Series, либо целый DataFrame.
Давайте посмотрим, что происходит, если мы передаём в параметр data= один столбец:
Мы можем видеть, что при вызове этой функции она возвращает DataFrame. Это очень удобно, но, к сожалению, в результат не включаются остальные столбцы исходного набора данных.
Давайте посмотрим, как можно передать в параметр data= целый DataFrame и выполнить one-hot кодирование только для одного столбца:
Мы можем видеть, что результатом является исходный DataFrame, в котором столбец Gender был подвергнут one-hot кодированию.
Работа с пропущенными данными при использовании get_dummies в Pandas
get_dummies в PandasВ этом разделе вы узнаете, как обрабатывать пропущенные значения при выполнении one-hot кодирования с помощью функции pd.get_dummies().
По умолчанию большинство моделей машинного обучения не могут работать с пропущенными данными. Это означает, что вы можете либо удалить такие строки, либо заполнить пропуски (импутировать).
Это также касается и one-hot кодирования — по умолчанию функция pd.get_dummies() игнорирует пропущенные значения. Давайте посмотрим, как это проявляется при кодировании столбца House Type:
В приведённом выше блоке кода мы выполнили one-hot кодирование столбца House Type, в котором было пропущенное значение на позиции индекса 3. Мы можем видеть, что ни один из новых закодированных столбцов не содержит значения для этой строки.
Это поведение можно изменить, включив обработку пропущенных значений с помощью параметра dummy_na=, который по умолчанию установлен в False. Давайте установим это значение в True и посмотрим, как изменится результат:
Мы можем видеть, что теперь добавлен новый столбец, обозначающий наличие пропущенных данных в этом поле.
One-Hot кодирование нескольких столбцов с помощью get_dummies в Pandas
get_dummies в PandasВ этом разделе вы узнаете, как выполнить one-hot кодирование сразу нескольких столбцов с помощью функции pd.get_dummies().
Во многих случаях требуется закодировать не один, а несколько категориальных столбцов. Pandas делает это очень удобным и простым процессом.
Для этого достаточно передать DataFrame в параметр data=, а в параметр columns= указать список столбцов, которые вы хотите закодировать. Давайте посмотрим, как это работает:
Мы можем видеть, насколько просто выполнять one-hot кодирование нескольких столбцов с помощью функции pd.get_dummies().
Изменение разделителя в названиях закодированных столбцов в Pandas get_dummies
Pandas также позволяет легко изменить символ-разделитель, используемый при формировании названий новых столбцов после one-hot кодирования. По умолчанию используется символ подчёркивания _, чтобы отделить префикс от значения переменной. Это поведение можно изменить с помощью параметра prefix_sep=.
В приведённом выше примере мы увидели, что столбец 'House Type' содержал пробел. По этой причине использование символа подчёркивания выглядит немного неуклюже. Давайте изменим разделитель на пробел:
Заключение
В этом руководстве вы узнали, как выполнять one-hot кодирование данных с помощью функции pd.get_dummies() в Pandas. Вы ознакомились с тем, что такое one-hot кодирование и как оно используется в машинном обучении. Также вы научились:
Применять
get_dummies()для кодирования отдельных и нескольких столбцов,Включать пропущенные значения в процесс кодирования с помощью параметра
dummy_na=,Настройка разделителей и префиксов новых столбцов с помощью параметров
prefix=иprefix_sep=,Интегрировать результаты обратно в исходный DataFrame.
Теперь вы можете эффективно обрабатывать категориальные данные для использования в моделях машинного обучения.
Часто задаваемые вопросы
Вопрос: Что лучше использовать — pd.get_dummies или OneHotEncoder из Scikit-Learn?
Ответ: Оба метода выполняют one-hot кодирование, но OneHotEncoder из Scikit-Learn интегрируется в ML-пайплайны и позволяет применять одинаковое кодирование к обучающим и тестовым данным. Это особенно важно при развертывании моделей. Однако
Вопрос: В чём разница между one-hot encoding и dummy encoding?
Ответ: One-hot кодирование создаёт n новых столбцов для n уникальных значений, тогда как dummy кодирование создаёт n-1 столбец, чтобы избежать мультиколлинеарности. В Pandas по умолчанию используется one-hot кодирование, но его можно изменить, установив drop_first=True.
Дополнительные ресурсы
Чтобы углубить свои знания, ознакомьтесь со следующими материалами:
One-Hot кодирование в Scikit-Learn с использованием OneHotEncoder
Введение в Pandas для науки о данных
Группировка данных в Pandas с помощью cut и qcut
Последнее обновление