> For the complete documentation index, see [llms.txt](https://bemind.gitbook.io/neural/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://bemind.gitbook.io/neural/uchebniki-po-pandas-i-numpy/pandas/uchebnoe-posobie-po-python-pandas-polnoe-rukovodstvo.md).
# Учебное пособие по Python Pandas: полное руководство
В этом руководстве **вы узнаете о библиотеке pandas в Python!** Библиотека позволяет работать с табличными данными в привычном и доступном формате. pandas предлагает невероятную простоту, когда это необходимо, но также позволяет глубоко погружаться в поиск, манипулирование и агрегирование данных. pandas - одна из самых ценных библиотек для преобразования данных в языке Python и может быть расширена с помощью многих библиотек машинного обучения в Python.
Оглавление
* [Что такое библиотека Python Pandas](#chto-takoe-biblioteka-python-pandas)
* [Зачем вам нужны Pandas?](#zachem-vam-nuzhny-pandas)
* [Установка и импорт Pandas](#ustanovka-i-import-pandas)
* [Типы данных Pandas: серии и фреймы данных](#tipy-dannykh-pandas-serii-i-freimy-dannykh)
* [Создание фреймов данных Pandas с нуля](#sozdanie-freimov-dannykh-pandas-s-nulya)
* [Загрузка списка кортежей в DataFrame pandas](#zagruzka-spiska-kortezhei-v-dataframe-pandas)
* [Загрузка списка слов в DataFrame pandas](#zagruzka-spiska-slovarei-v-dataframe-pandas)
* [Чтение данных в кадры данных Pandas](#chtenie-dannykh-v-pandas-dataframes)
* [Просмотр данных в Pandas](#prosmotr-dannykh-v-pandas)
* [Что составляет фрейм данных Pandas](#chto-sostavlyaet-freim-dannykh-pandas)
* [Выбор столбцов и строк в Pandas](#vybor-stolbcov-i-strok-v-pandas)
* [Использование .iloc и .loc для выбора данных в Pandas](#ispolzovanie-.iloc-i-.loc-dlya-vybora-dannykh-v-pandas)
* [Выбор целых строк и столбцов](#vybor-celykh-strok-i-stolbcov)
* [Фильтрация данных в таблицах данных Pandas](#filtraciya-dannykh-v-tablicakh-dannykh-pandas)
* [Запись фреймов данных Pandas в файлы](#zapis-freimov-dannykh-pandas-v-faily)
* [Описание данных с помощью Pandas](#opisanie-dannykh-s-pomoshyu-pandas)
* [Анализ данных с помощью Pandas](#analiz-dannykh-s-pomoshyu-pandas)
* [Сортировка данных и работа с повторяющимися данными](#sortirovka-dannykh-i-rabota-s-povtoryayushimisya-dannymi)
* [Как сортировать данные в таблице данных Panda](#kak-sortirovat-dannye-v-tablice-dannykh-pandas)s
* [Как работать с повторяющимися данными в таблице данных Pandas](#kak-rabotat-s-povtoryayushimisya-dannymi-v-tablice-dannykh-pandas)
* [Работа с недостающими данными в Pandas](#rabota-s-nedostayushimi-dannymi-v-pandas)
* [Как удалить недостающие данные в Pandas](#kak-udalit-nedostayushie-dannye-v-pandas)
* [Как заполнить недостающие данные в Pandas](#kak-zapolnit-nedostayushie-dannye-v-pandas)
* [Сводные таблицы Pandas и изменение формы данных](#svodnye-tablicy-pandas-i-izmenenie-formy-dannykh)
* [Группировка данных с помощью Pandas Group By](#gruppirovka-dannykh-s-pomoshyu-pandas-group-by)
* [Работа с датами в Pandas](#rabota-s-datami-v-pandas)
* [Объединение данных с Pandas](#obedinenie-dannykh-s-pandas)
* [Добавление фреймов данных Pandas с помощью .concat()](#dobavlenie-freimov-dannykh-pandas-s-pomoshyu-.concat)
* [Объединение фреймов данных Pandas с использованием .merge()](#obedinenie-freimov-dannykh-pandas-s-ispolzovaniem-.merge)
* [Что дальше?](#chto-dalshe)
### Что такое библиотека Python Pandas
Pandas - это библиотека Python, которая позволяет работать с быстрыми и гибкими структурами данных: `Series` и `DataFrame` в Pandas. Библиотека предоставляет высокоуровневый синтаксис, позволяющий использовать знакомые функции и методы. Pandas предназначена для работы в любой отрасли, включая финансы, статистику, социальные науки и инженерию.
Библиотека стремится стать самым мощным и гибким инструментом для анализа данных с открытым исходным кодом на любом языке программирования. Она определенно успешно движется к этой цели!
Библиотека pandas позволяет работать со следующими типами данных:
* Табличные данные с колонками различных типов данных, такие как из таблиц Excel, файлов CSV из интернета и таблиц баз данных SQL
* Данные временных рядов с фиксированной частотой или без нее
* Другие структурированные наборы данных, такие как данные из веба, например, файлы JSON
Pandas предоставляет две основные структуры данных для работы: одномерный объект `Series` и двумерный объект `DataFrame`. Мы более подробно рассмотрим их чуть позже, но давайте на мгновение остановимся и рассмотрим некоторые из множества преимуществ, которые предоставляет библиотека pandas.
### Зачем вам нужны Pandas?
Pandas - это основополагающая библиотека для анализа данных в Python (и, возможно, и в других языках тоже). Она гибкая, легка в освоении и невероятно мощная. Давайте рассмотрим некоторые вещи, которые библиотека делает очень хорошо:
* **Чтение, доступ и просмотр данных** в привычных табличных форматах
* Манипулирование DataFrames для добавления, удаления и вставки данных
* Простые способы работы с ***отсутствующими данными***
* Знакомые способы агрегирования данных с помощью Pandas **Pivot\_table** и группировки данных с помощью метода **group\_by**.
* Универсальное **преобразование наборов данных**, такое как изменение формата с широкого на длинный или с длинного на широкий
* Простой интерфейс построения графиков для быстрой **визуализации данных**
* Простое и понятное объединение наборов данных.
* Мощная **функциональность временных рядов**, такая как конвертация частоты, скользящие окна и лагирование
* **Иерархические оси** добавляют дополнительную глубину к вашим данным
Это даже близко не охватывает все функциональные возможности, которые предоставляет Pandas, но подчёркивает многие важные аспекты. Давайте начнем погружение в библиотеку, чтобы лучше понять, что она предлагает.
### Установка и импорт Pandas
Pandas не является частью стандартной библиотеки Python. Из-за этого нам необходимо установить его перед тем, как мы сможем его использовать. Мы можем сделать это с помощью менеджеров пакетов `pip` или `conda`
В зависимости от используемого вами менеджера пакетов используйте одну из команд ниже. Если вы используете `pip`, используйте команду ниже:
```python
pip install pandas
```
В качестве альтернативы, если вы используете `conda`, используйте следующую команду:
```python
conda install pandas
```
По соглашению, библиотека pandas импортируется с псевдонимом `pd`. Хотя вы можете использовать любой псевдоним, которы повзрастаете, следование этому соглашению поможет другим легче понять ваш код. Давайте посмотрим, как мы можем импортировать библиотеку в скрипт на Python:
```python
# How to import the pandas library in a Python script
import pandas as pd
```
Теперь, когда мы запустились, давайте рассмотрим различные типы данных, которые предлагает библиотека: `Series` и `DataFrame`.
### Типы данных Pandas: серии и фреймы данных
Pandas предоставляет доступ к двум структурам данных:
1. Структура `Series` в библиотеке pandas представляет собой одномерный однородный массив.
2. Структура `DataFrame` из библиотеки pandas представляет собой двумерную, изменяемую и потенциально гетерогенную структуру данных.
На этом этапе вы, возможно, задаетесь вопросом, почему в pandas есть несколько структур данных. Идея заключается в том, что pandas позволяет получить доступ к данным низкого уровня с помощью простых методов, подобных работе со словарем. Сам DataFrame содержит объекты Series, а Series содержат отдельные скалярные точки данных.
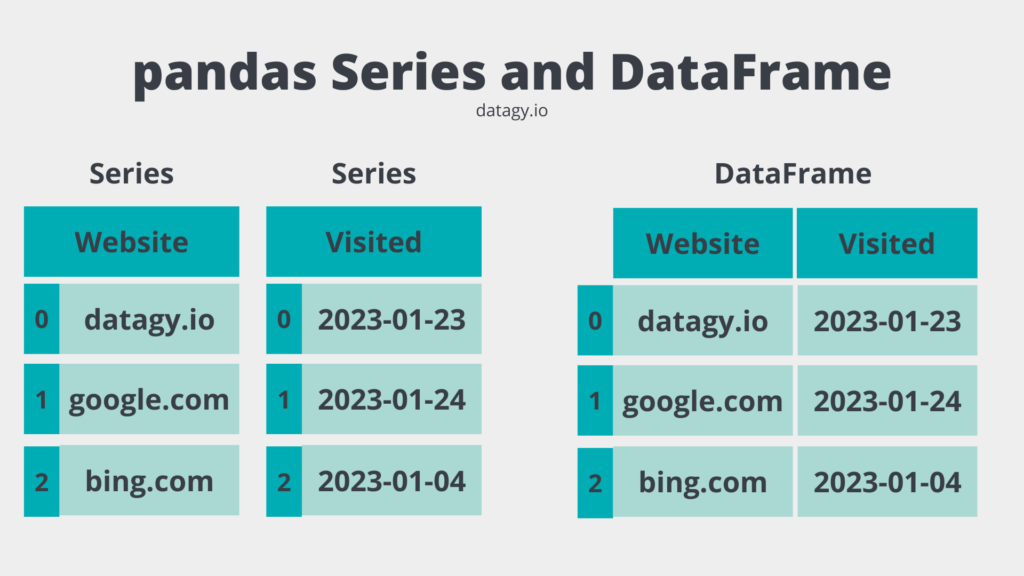
Взгляните на изображение ниже. Можно считать, что объект Series в pandas - это столбец в табличном наборе данных. Pandas гарантирует, что данные в объекте Series однородны, то есть содержат только один тип данных. В то время как объект DataFrame в pandas содержит несколько объектов Series, которые имеют общий индекс. Благодаря этому DataFrame может быть гетерогенным.
Понимание серий Pandas и DataFrames
Так как DataFrame является контейнером для Series, они также используют похожий язык для доступа, манипулирования и работы с данными. Подобным образом, предоставляя две структуры данных, pandas значительно упрощает работу с двумерными данными.
В этом руководстве мы сосредоточимся в основном на структуре данных DataFrame библиотеки Pandas. Это обусловлено тем, что именно с этой структурой данных вам придется сталкиваться наиболее часто в повседневной работе. Теперь давайте рассмотрим, как мы можем создать DataFrame в Pandas с нуля.
### Создание фреймов данных Pandas с нуля
Для создания объекта DataFrame в Pandas вы можете напрямую передать данные в конструктор `pd.DataFrame()`. Это позволяет использовать различные структуры данных Python, такие как списки, словари или кортежи.
#### Загрузка списка кортежей в DataFrame pandas
Pandas может делать предположения о передаваемых данных, что уменьшает вашу рабочую нагрузку. Представьте, что вы работаете с данными, извлеченными из базы данных, где данные хранятся в виде списков кортежей. Например, вы можете столкнуться с данными, которые выглядят так:
```python
# Sample List of Tuples Dataset
data = [
('Nik', 34, '2022-12-12'),
('Katie', 33, '2022-12-01'),
('Evan', 35, '2022-02-02'),
('Kyra', 34, '2022-04-14')
]
```
Вы можете передать этот набор данных непосредственно в конструктор, и pandas самостоятельно определит, как разделить столбцы на осмысленный табличный набор данных. Давайте посмотрим, как это будет выглядеть:
```python
# Loading a List of Tuples into a Pandas DataFrame
import pandas as pd
data = [
('Nik', 34, '2022-12-12'),
('Katie', 33, '2022-12-01'),
('Evan', 35, '2022-02-02'),
('Kyra', 34, '2022-04-14')
]
df = pd.DataFrame(data)
print(df)
# Returns:
# 0 1 2
# 0 Nik 34 2022-12-12
# 1 Katie 33 2022-12-01
# 2 Evan 35 2022-02-02
# 3 Kyra 34 2022-04-14
```
Pandas успешно разобрал отдельные строки и столбцы набора данных. Каждый кортеж в списке интерпретируется как отдельная строка, в то время как каждый элемент кортежа распознаётся как столбец в наборе данных.
Обратите внимание, что pandas не присвоил имена столбцам. Это логично, так как мы не просили об этом! Вместо этого он использовал нумерацию с 0 по 2. Давайте посмотрим, как мы можем добавить значимые имена столбцов к DataFrame, используя параметр `columns=` в конструкторе.
```python
# Adding Columns Names to Our DataFrame
import pandas as pd
data = [
('Nik', 34, '2022-12-12'),
('Katie', 33, '2022-12-01'),
('Evan', 35, '2022-02-02'),
('Kyra', 34, '2022-04-14')
]
df = pd.DataFrame(data, columns=['Name', 'Age', 'Date Joined'])
print(df)
# Returns:
# Name Age Date Joined
# 0 Nik 34 2022-12-12
# 1 Katie 33 2022-12-01
# 2 Evan 35 2022-02-02
# 3 Kyra 34 2022-04-14
```
Из приведенного выше DataFrame мы видим, что было возможно передать список заголовков столбцов, используя параметр `columns=`. pandas упрощает и делает интуитивно понятным создание табличных данных, которые легко представляются в знакомом формате.
#### Загрузка списка словарей в DataFrame pandas
В других случаях вы можете получить данные в виде списка словарей. Думайте о загрузке данных JSON из веб-API – во многих случаях эти данные поступают в формате списка словарей. Посмотрите, как это выглядит ниже:
```python
# A List of Dictionaries
[{'Name': 'Nik', 'Age': 34, 'Date Joined': '2022-12-12'},
{'Name': 'Katie', 'Age': 33, 'Date Joined': '2022-12-01'},
{'Name': 'Evan', 'Age': 35, 'Date Joined': '2022-02-02'},
{'Name': 'Kyra', 'Age': 34, 'Date Joined': '2022-04-14'}]
```
Мы можем загрузить этот набор данных, снова, передав его напрямую в конструктор `pd.DataFrame()`, как показано ниже:
```python
# Loading a List of Dictionaries into a Pandas DataFrame
import pandas as pd
data = [
{'Name': 'Nik', 'Age': 34, 'Date Joined': '2022-12-12'},
{'Name': 'Katie', 'Age': 33, 'Date Joined': '2022-12-01'},
{'Name': 'Evan', 'Age': 35, 'Date Joined': '2022-02-02'},
{'Name': 'Kyra', 'Age': 34, 'Date Joined': '2022-04-14'}
]
df = pd.DataFrame(data)
print(df)
# Returns:
# Name Age Date Joined
# 0 Nik 34 2022-12-12
# 1 Katie 33 2022-12-01
# 2 Evan 35 2022-02-02
# 3 Kyra 34 2022-04-14
```
Как видно в приведенном выше блоке кода, нам не нужно было передавать имена столбцов. pandas автоматически использует ключи словаря для формирования заголовков столбцов.
Теперь, когда мы научились создавать DataFrame в pandas, давайте рассмотрим, как мы можем загружать в них готовые наборы данных.
### Чтение данных в Pandas DataFrames
Pandas предлагает множество функциональных возможностей для чтения различных типов данных в DataFrame. Например, вы можете читать данные из файлов Excel, текстовых файлов (например, CSV), SQL-баз данных, веб-API, хранящихся в данных JSON, и даже непосредственно со страниц веб
Давайте посмотрим, как загрузить CSV-файл. pandas предоставляет возможность загрузки набора данных либо в виде файла, хранящегося на вашем компьютере, либо в виде файла, который можно загрузить с веб-страницы. Взгляните на набор данных здесь. Вы можете скачать его или работать с ним как с веб-страницей (хотя, конечно, вам понадобится активное подключение к Интернету).
Pandas предлагает ряд специализированных функций для загрузки различных типов наборов данных:
* Функция `.read_csv()` в pandas используется для [чтения CSV-файлов в pandas DataFrame](https://datagy.io/pandas-read_csv/)
* Функция `.read_excel()` в pandas используется для [чтения файлов Excel в DataFrame pandas](https://datagy.io/pandas-read-excel/)
* Функция `.read_html()` в Pandas используется для [чтения таблиц HTML в DataFrame pandas](https://datagy.io/python-extract-tables-from-webpage/)
* The pandas `.read_parquet()` function is used for [reading parquet files into a pandas DataFrame](https://datagy.io/pandas-read-parquet/)
* Функция `.read_parquet()` в pandas используется для [чтения файлов parquet в pandas DataFrame](https://datagy.io/pandas-read-parquet/)
* и многое другое…
Давайте посмотрим, как мы можем использовать функцию `read_csv()` из библиотеки pandas для чтения только что описанного нами CSV
```python
# Loading a CSV File into a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df)
# Returns:
# Date Region Type Units Sales
# 0 2020-07-11 East Children's Clothing 18.0 306.0
# 1 2020-09-23 North Children's Clothing 14.0 448.0
# 2 2020-04-02 South Women's Clothing 17.0 425.0
# 3 2020-02-28 East Children's Clothing 26.0 832.0
# 4 2020-03-19 West Women's Clothing 3.0 33.0
# .. ... ... ... ... ...
# 995 2020-02-11 East Children's Clothing 35.0 735.0
# 996 2020-12-25 North Men's Clothing NaN 1155.0
# 997 2020-08-31 South Men's Clothing 13.0 208.0
# 998 2020-08-23 South Women's Clothing 17.0 493.0
# 999 2020-08-17 North Women's Clothing 25.0 300.0
# [1000 rows x 5 columns]
```
Давайте разберем, что мы сделали в приведенном выше блоке кода:
1. Мы импортировали библиотеку pandas с использованием стандартного псевдонима `pd`
2. Мы затем создали новую переменную `df`, которая является стандартным способом создания DataFrame в pandas. Для этой переменной мы использовали функцию `pd.read_csv()`, которая требует только строку с путем к файлу. pandas может читать файлы, размещенные как в Интернете, так и на вашем локальном компьютере. В данном случае мы используем набор данных, размещенный в Интернете.
3. Наконец, мы вывели DataFrame с помощью функции `print()` Python. Pandas отобразил первые пять записей и последние пять записей. Однако он также предоставил информацию о реальном размере набора данных, указывая, что он включает 1000 строк и 5 столбцов.
**Совет!** Pandas упрощает [подсчёт количества строк в DataFrame](https://datagy.io/pandas-number-of-rows/), а также подсчет [количества столбцов в DataFrame](https://datagy.io/pandas-number-of-columns/) с использованием специальных методов.
Python и pandas будут усекать DataFrame в зависимости от размера вашего терминала и размера самого DataFrame. Вы можете контролировать это гораздо более детально, заставив pandas [показать все строки и столбцы](https://datagy.io/pandas-show-all-columns-rows/). Однако, мы также можем попросить pandas показать конкретные данные, используя дополнительные методы. Давайте изучим это дальше.
### Просмотр данных в Pandas
Pandas предоставляет множество функций для просмотра данных, хранящихся в DataFrame. Как вы уже узнали, вы можете напечатать DataFrame, просто передав его в функцию Python `print()`. В зависимости от объема хранимых данных вывод может быть усечен.
Мы можем использовать различные методы DataFrame, чтобы узнать больше о наших данных. Например:
* Метод `.head(n)` возвращает первые `n` строк DataFrame (по умолчанию возвращается пять строк).
* Метод `.last(n)` возвращает последние `n` строк DataFrame (по умолчанию возвращает пять строк).
* доступы вроде `.iloc[x:y, :]` вернут строки с `x` по `y-1`,
* и многое другое
Давайте посмотрим, как мы можем погрузиться в анализ некоторых данных, используя эти методы. Сначала мы выведем на печать первые пять строк DataFrame:
```python
# Printing the First Five Rows of a DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.head())
# Returns:
# Date Region Type Units Sales
# 0 2020-07-11 East Children's Clothing 18.0 306.0
# 1 2020-09-23 North Children's Clothing 14.0 448.0
# 2 2020-04-02 South Women's Clothing 17.0 425.0
# 3 2020-02-28 East Children's Clothing 26.0 832.0
# 4 2020-03-19 West Women's Clothing 3.0 33.0
```
Обратите внимание, что в приведенном выше блоке кода нам не потребовалось передавать число в метод `.head()`. По умолчанию pandas будет использовать значение 5. Это позволяет вам легко вывести первые пять строк DataFrame.
Аналогичным образом, мы можем выводить последние `n` записей DataFrame. Метод `.tail()` по умолчанию выводит пять записей, так же как и метод `.head()`. Давайте посмотрим, как мы можем использовать этот метод, чтобы указать желание вывести последние три записи:
```python
# Printing the Last n Rows of a DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.tail(3))
# Returns:
# Date Region Type Units Sales
# 997 2020-08-31 South Men's Clothing 13.0 208.0
# 998 2020-08-23 South Women's Clothing 17.0 493.0
# 999 2020-08-17 North Women's Clothing 25.0 300.0
```
Мы видим, насколько это было просто! Мы оставим использование акцессора `.iloc` для более позднего раздела, поскольку это выходит за рамки простого возвращения строк. А пока давайте немного погрузимся в то, из чего на самом деле состоит pandas DataFrame.
### Что составляет фрейм данных Pandas
Прежде чем мы углубимся в работу с DataFrame в pandas, давайте исследуем, из чего же на самом деле состоит DataFrame. Сама документация библиотеки pandas определяет DataFrame как:
> Двумерные, изменяемые по размеру, потенциально гетерогенные табличные данные.
>
> Документация pandas DataFrame *(*[*link*](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.html)*)*
* **двумерный** означает, что он имеет как строки, так и столбцы.
* **размер-изменяемый** означает, что размер и форма могут изменяться по мере роста DataFrame или изменения его формы, и
* **потенциально гетерогенный** означает, что тип данных может различаться в разных столбцах
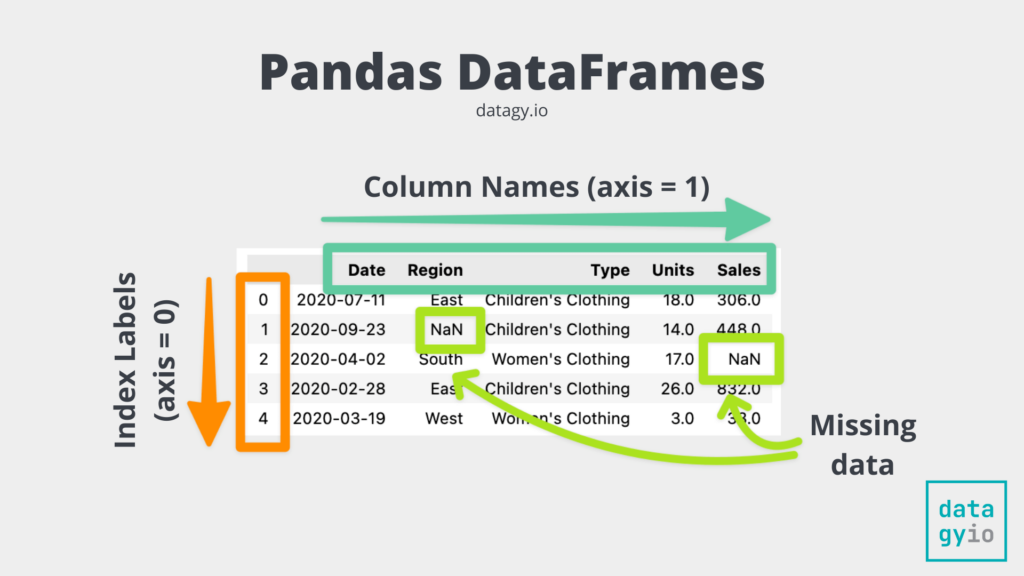
Теперь, когда мы знаем, чем может быть DataFrame, давайте рассмотрим, из чего он состоит. Посмотрите на изображение ниже, которое представляет собой красиво отформатированную версию нашего DataFrame:
Что составляет DataFrame Pandas
Давайте рассмотрим отдельные компоненты объекта DataFrame в pandas:
* **Индекс** представляет собой метки "строк" набора данных. В Pandas индекс также представлен как ось 0. Вы можете видеть, как индексы нашего DataFrame выделены жирным от 0 до конца. В данном случае метки индексов являются произвольными, но также могут представлять уникальные, понятные значения.
* **Столбцы** представлены первой осью DataFrame и состоят из отдельных объектов pandas Series. Каждый столбец может иметь уникальный тип данных, однако, соединяясь вместе, DataFrame может быть гетерогенным.
* Фактические данные могут быть разных типов, включая даты. Данные также могут содержать пропущенные значения, представленные значениями `NaN` (не число).
Теперь, когда у вас есть хорошее понимание того, как строятся DataFrame, давайте вернемся к выбору данных.
### Выбор столбцов и строк в Pandas
Pandas предоставляет множество простых способов выбора данных, будь то строки, столбцы или перекрестные сечения. Давайте сначала рассмотрим некоторые общие варианты. Представьте, что мы работаем с тем же DataFrame, который мы использовали до сих пор, и он выглядит следующим образом:
```python
# Showing Our DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.head())
# Returns:
# Date Region Type Units Sales
# 0 2020-07-11 East Children's Clothing 18.0 306.0
# 1 2020-09-23 North Children's Clothing 14.0 448.0
# 2 2020-04-02 South Women's Clothing 17.0 425.0
# 3 2020-02-28 East Children's Clothing 26.0 832.0
# 4 2020-03-19 West Women's Clothing 3.0 33.0
```
В таблице ниже приведены различные варианты, которые у нас есть для выбора данных в нашем DataFrame Pandas:
1. `df.iloc[]` используется для выбора значений на основе их целочисленного положения.
2. `df.loc[]` используется для выбора значений по их меткам.
3. `df[col_name]` используется для выбора целого столбца (или списка столбцов) данных.
4. `df[n]` используется для возвращения одной строки (или диапазона строк)
#### Использование .iloc и .loc для выбора данных в Pandas
Давайте посмотрим, как мы можем использовать аксессор `.iloc[]` для выбора некоторых строк и данных из нашего DataFrame в pandas:
```python
# Using .iloc to Select Data
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.iloc[0,0])
# Returns: 2020-07-11
```
Pandas, как и Python, использует индексацию с 0. Это означает, что на каждой из осей данные начинаются с индекса 0. Из-за этого использование `df.iloc[0,0]` вернёт значение из первой строки и первого столбца.
Точно так же мы можем использовать акцессор `.loc[]` для доступа к значениям на основе их меток. Поскольку наш индекс использует произвольные метки, мы укажем выборку, используя номер строки, как показано ниже:
```python
# Using .loc to Select Data
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.loc[1,'Units'])
# Returns: 14.0
```
В приведенном выше коде мы просили Pandas выбрать данные из строки с индексом 1 (наша вторая строка) и из столбца `'Units'`. Этот метод может быть гораздо более понятным, когда наши метки индексов являются интуитивно понятными, например, когда используются даты или конкретные люди.
Мы также можем выбирать диапазон данных с помощью срезов. Методы `.iloc` и `.loc` позволяют вам передавать срезы данных, например, `df.iloc[:4, :]`, что вернет строки с 0 по 3 и все столбцы.
#### Выбор целых строк и столбцов
Вы также можете выбрать целые строки и столбцы данных. Pandas принимает числовые значения и диапазоны для выбора целых строк данных. Например, если вы хотите выбрать строки с позициями с 3 по 10, вы можете использовать следующий код:
```python
# Selecting a Range of Rows in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df[3:10])
# Returns:
# Date Region Type Units Sales
# 3 2020-02-28 East Children's Clothing 26.0 832.0
# 4 2020-03-19 West Women's Clothing 3.0 33.0
# 5 2020-02-05 North Women's Clothing 33.0 627.0
# 6 2020-01-24 South Women's Clothing 12.0 396.0
# 7 2020-03-25 East Women's Clothing 29.0 609.0
# 8 2020-01-03 North Children's Clothing 18.0 486.0
# 9 2020-11-03 East Children's Clothing 34.0 374.0
# 10 2020-04-16 South Women's Clothing 16.0 352.0
```
Мы видим, что в это включены данные до метки строки 10, но не включая её. Стоит отметить, что здесь мы смогли не использовать акцессор `.iloc[]`. pandas может самостоятельно определить, что мы хотим выбрать строки.
Точно так же, вы можете выбрать целый столбец, просто указав его имя. Это вернет серию Pandas, как показано ниже:
```python
# Selecting a Column from a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df['Date'])
# Returns:
# 0 2020-07-11
# 1 2020-09-23
# 2 2020-04-02
# 3 2020-02-28
# 4 2020-03-19
# ...
# 995 2020-02-11
# 996 2020-12-25
# 997 2020-08-31
# 998 2020-08-23
# 999 2020-08-17
# Name: Date, Length: 1000, dtype: object
```
Вы также можете выбрать несколько разных столбцов. Для этого передайте список в индексацию. Давайте выберем столбцы `'Дата'` и `'Type'`
```python
# Selecting Columns from a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df[['Date', 'Type']])
# Returns:
# Date Type
# 0 2020-07-11 Children's Clothing
# 1 2020-09-23 Children's Clothing
# 2 2020-04-02 Women's Clothing
# 3 2020-02-28 Children's Clothing
# 4 2020-03-19 Women's Clothing
# .. ... ...
# 995 2020-02-11 Children's Clothing
# 996 2020-12-25 Men's Clothing
# 997 2020-08-31 Men's Clothing
# 998 2020-08-23 Women's Clothing
# 999 2020-08-17 Women's Clothing
# [1000 rows x 2 columns]
```
Обратите внимание, что мы можем выбрать столбцы, даже если они не расположены рядом друг с другом! Это действие возвращает DataFrame в Pandas.
Чтобы узнать больше о выборе и поиске данных, ознакомьтесь с ресурсами ниже:
* Как индексировать, выбирать и назначать данные в Pandas
* Как выбрать столбцы в Pandas
* Как перетасовать строки данных Pandas в Python
* Как выполнить выборку данных в DataFrame Pandas
* Как разделить фрейм данных Pandas
* Изменение порядка столбцов Pandas: переиндексация Pandas и вставка Pandas
* Pandas: как удалить столбец индекса Dataframe
* Индекс сброса Pandas: как сбросить индекс Pandas
* Индекс переименования Pandas: как переименовать индекс Dataframe Pandas
### Фильтрация данных в таблицах данных Pandas
Pandas упрощает фильтрацию данных в вашем DataFrame. Фактически, он предлагает множество различных способов фильтрации вашего набора данных. В этом разделе мы рассмотрим некоторые из этих методов и предоставим вам дополнительные ресурсы для углубления ваших навыков.
Давайте посмотрим, что происходит, когда мы применяем логический оператор к столбцу DataFrame в pandas:
```python
# Applying a Boolean Operator to a Pandas Column
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv', parse_dates=['Date'])
print(df['Units'] > 30)
# Returns:
# 0 False
# 1 False
# 2 False
# 3 False
# 4 False
# ...
# 995 True
# 996 False
# 997 False
# 998 False
# 999 False
# Name: Units, Length: 1000, dtype: bool
```
Когда мы применяем булев оператор к столбцу DataFrame в pandas, это возвращает серию данных типа boolean. На первый взгляд, это может показаться не очень полезным. **Однако, мы можем индексировать наш DataFrame с помощью этой серии для фильтрации наших данных!** Давайте посмотрим, как это выглядит:
```python
# Filtering a Pandas DataFrame with Logical Operators
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv', parse_dates=['Date'])
print(df[df['Units'] > 30])
# Returns:
# Date Region Type Units Sales
# 5 2020-02-05 North Women's Clothing 33.0 627.0
# 9 2020-11-03 East Children's Clothing 34.0 374.0
# 16 2020-06-12 East Women's Clothing 35.0 1050.0
# 18 2020-06-16 North Women's Clothing 34.0 884.0
# 20 2020-09-14 North Children's Clothing 35.0 630.0
# .. ... ... ... ... ...
# 973 2020-10-04 East Men's Clothing 35.0 350.0
# 977 2020-10-20 East Men's Clothing 32.0 928.0
# 985 2020-02-08 West Men's Clothing 32.0 928.0
# 987 2020-04-23 South Women's Clothing 34.0 680.0
# 995 2020-02-11 East Children's Clothing 35.0 735.0
# [146 rows x 5 columns]
```
Мы видим, что индексируя наш DataFrame с помощью логического условия, pandas фильтрует наш DataFrame.
Pandas также предоставляет полезный метод для фильтрации DataFrame. Это можно сделать с помощью метода `.query()` в Pandas, который позволяет вам использовать запросы на обычном языке для фильтрации вашего DataFrame.
Давайте углубимся в изучение функции `query()` Pandas, чтобы лучше понять параметры и аргументы по умолчанию, которые предоставляет эта функция.
```python
# Understanding the Pandas query() Function
import pandas as pd
DataFrame.query(expr, inplace=False, **kwargs)
```
Мы видим, что функция `query()` в Pandas имеет два параметра:
1. `expr=` представляет выражение, которое используется для фильтрации DataFrame
2. `inplace=` указывает Pandas выполнить фильтрацию DataFrame на месте, по умолчанию установлено в False
Метод `.query()` библиотеки Pandas позволяет передать строку, которая представляет выражение фильтра. На первый взгляд, синтаксис может показаться немного непривычным, но если вы знакомы с SQL, формат покажется очень естественным. Давайте рассмотрим пример, где мы фильтруем DataFrame, чтобы показать только те строки, где количество единиц меньше 4.
```python
import pandas as pd
df = pd.read_excel(
'https://github.com/datagy/mediumdata/raw/master/sample_pivot.xlsx',
parse_dates=['Date']
)
filtered = df.query('Units < 4')
print(filtered.head())
# Returns:
# Date Region Type Units Sales
# 4 2020-03-19 West Women's Clothing 3.0 33
# 28 2020-01-19 East Men's Clothing 3.0 63
# 96 2020-11-13 East Children's Clothing 3.0 72
# 118 2020-12-28 East Children's Clothing 3.0 78
# 134 2020-09-04 North Children's Clothing 3.0 184
```
Мы можем увидеть, что, передавая строку, которая представляет выражение, в данном случае `'Units < 4'`, мы отфильтровали числовой столбец.
Метод query в Pandas также может использоваться для фильтрации с несколькими условиями. Это позволяет нам указать условия, используя логические операторы `and` или `or`. Используя несколько условий, мы можем написать мощные инструкции, которые фильтруют данные на основе одного или нескольких столбцов.
Давайте посмотрим, как мы можем использовать метод для фильтрации данных на основе столбцов Регион и Единицы.
```python
import pandas as pd
df = pd.read_excel(
'https://github.com/datagy/mediumdata/raw/master/sample_pivot.xlsx',
parse_dates=['Date']
)
filtered = df.query('Region == "West" and Units < 4')
print(filtered.head())
# Returns:
# Date Region Type Units Sales
# 4 2020-03-19 West Women's Clothing 3.0 33
# 135 2020-01-07 West Women's Clothing 3.0 350
# 355 2020-06-12 West Children's Clothing 3.0 567
# 558 2020-10-06 West Men's Clothing 3.0 462
# 686 2020-02-18 West Men's Clothing 3.0 918
```
В приведенном выше примере мы передаем два условия: одно основано на числовом столбце, а другое - на строковом. Мы используем оператор `and`, чтобы убедиться, что оба условия выполнены.
Чтобы узнать больше о том, как фильтровать DataFrame в pandas, ознакомьтесь с ресурсами ниже:
* Как отфильтровать фрейм данных Pandas
* Как использовать запрос Pandas для фильтрации фрейма данных
* Как использовать Pandas Isin для фильтрации кадра данных, например SQL IN и NOT IN
### Запись фреймов данных Pandas в файлы
Мы уже рассмотрели, как загружать данные и просматривать их. Ещё один важный аспект, который, вероятно, вас интересует, - это способы сохранения DataFrame, с которыми вы работаете. К счастью, pandas поддерживает множество различных типов файлов для сохранения. Многие из этих методов имеют логичные названия: например, `.to_excel()` используется для сохранения DataFrame в файл Excel.
Давайте посмотрим, как мы можем использовать метод pandas `.to_csv()` для сохранения DataFrame в файл CSV. Этот метод обеспечивает большую гибкость с точки зрения сохранения данных. Например, вы можете включить или исключить индекс DataFrames при сохранении файла.
```python
# Saving a Pandas DataFrame to a CSV File
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
df.to_csv('file.csv', sep=';', index=False)
```
В приведенном выше примере мы использовали метод `.to_csv()` для сохранения pandas DataFrame в файл CSV. Обратите внимание, что мы использовали три параметра:
1. `'file.csv'` — это имя файла, в который мы хотим сохранить файл,
2. `'sep=;'` указывает на то, что файл должен быть разделён точками с запятой.
3. `index=False` указывает на то, что мы хотим сохранить файл без включения индекса.
Часто индекс не указывают, когда он является произвольным. В нашем случае индекс представляет только номер строки. Исходя из этого, имеет смысл исключить его из нашего результирующего файла.
Чтобы сохранить pandas DataFrames в различных форматах данных, вы можете использовать следующие методы:
* Метод `.to_excel()` в pandas используется для сохранения DataFrame в файлы Excel
* Метод `.to_csv()` в pandas используется для сохранения DataFrame pandas в файлы CSV
* Метод `.values.tolist()` в pandas используется для сохранения pandas DataFrames в списки Python
* Метод `.to_dict()` в pandas используется для сохранения DataFrame pandas в словари Python
* Метод `.to_json()` в pandas используется для сохранения pandas DataFrames в JSON файлы
* Метод `.to_pickle()` в Pandas используется для сохранения DataFrame'ов Pandas в файлы pickle
Давайте теперь рассмотрим, как использовать Pandas для описания нашего набора данных.
### Описание данных с помощью Pandas
Pandas предлагает множество различных способов анализа ваших данных. Однако часто может быть очень полезно сначала получить представление о данных в вашем DataFrame. Для этого вы можете использовать два основных метода DataFrame:
1. `.info()` предоставляет информацию о самом DataFrame.
2. `.describe()` предоставляет информацию о данных в DataFrame
Давайте сначала рассмотрим метод `.info()`. Этот метод можно применить непосредственно к DataFrame, и он вернет информацию о DataFrame, такую как его размер, столбцы и многое другое. Давайте посмотрим, что произойдет, когда мы напечатаем результат метода `df.info()`
```python
# Using the .info() Method to Display Information
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.info())
# Returns:
#
# RangeIndex: 1000 entries, 0 to 999
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Date 1000 non-null object
# 1 Region 1000 non-null object
# 2 Type 1000 non-null object
# 3 Units 911 non-null float64
# 4 Sales 1000 non-null float64
# dtypes: float64(2), object(3)
# memory usage: 39.2+ KB
```
В приведенном выше блоке кода мы видим, что метод возвращает множество полезной информации. Например, мы видим, что индекс является `RangeIndex`, что означает, что он содержит значения от 0 до 999.
Аналогично, мы можем увидеть, что DataFrame содержит пять столбцов. Мы также можем увидеть их типы данных и сколько ненулевых значений содержится в каждом столбце. Наконец, мы можем увидеть использование памяти DataFrame.
Теперь давайте рассмотрим метод `.describe()`, который позволяет описать данные, находящиеся в самом DataFrame. Это позволяет вам видеть информацию о числовых столбцах, предоставляя статистику высокого уровня.
```python
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.describe())
# Returns:
# Units Sales
# count 911.000000 1000.000000
# mean 19.638858 427.254000
# std 9.471309 253.441362
# min 3.000000 33.000000
# 25% 12.000000 224.000000
# 50% 20.000000 380.000000
# 75% 28.000000 575.000000
# max 35.000000 1155.000000
```
Мы видим, что метод вернул полезную информацию, такую как количество точек данных, средние значения, стандартное отклонение и другую статистику.
Чтобы узнать больше о методе `.describe()` в pandas, этот гид предоставляет вам всё, что вам нужно знать о методе describe
### Анализ данных с помощью Pandas
Будучи библиотекой аналитики, pandas предлагает массу различных опций для анализа ваших данных. Фактически, есть встроенные методы практически для всего, что вы можете захотеть сделать. Если их нет, создать свои собственные методы просто и интуитивно понятно.
Давайте сначала рассмотрим некоторую базовую дескриптивную статистику. Многие методы имеют легко понимаемые названия. Например, чтобы рассчитать среднее значение, можно использовать метод `.mean()`. Вот где API Pandas становится еще более интересным. **Множество методов доступны как для объектов pandas Series, так и для DataFrames**. pandas изменит результирующий вывод в зависимости от того, к какому типу объекта применяется метод. Давайте посмотрим, как мы можем рассчитать среднее значение для столбца pandas сначала:
```python
# Calculating the Mean of a Pandas Column
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df['Sales'].mean())
# Returns: 427.254
```
Мы можем видеть, что когда мы применяем метод к одному столбцу pandas Series, метод возвращает одно скалярное значение. В данном случае это значение составляет 427.254.
Аналогичным образом, мы можем применить метод ко всему DataFrame. Давайте посмотрим, как это изменит вывод:
```python
# Calculating the Mean for a DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.mean(numeric_only=True))
# Returns:
# Units 19.638858
# Sales 427.254000
# dtype: float64
```
При применении метода `.mean()` ко всему DataFrame необходимо использовать аргумент `numeric=True`, указывая на то, что мы хотим применить метод только к числовым столбцам DataFrame. Таким образом, pandas вернёт серию данных. Это означает, что мы можем получить доступ к отдельным средним значениям, индексируя их.
Pandas предоставляет множество других методов для вычисления статистики. Вы можете узнать о них больше, изучив предложенные ниже ресурсы. Вы даже можете использовать пользовательские функции и работать с ними, чтобы [трансформировать столбцы в pandas](https://datagy.io/pandas-map-apply/) с помощью методов `.map()` и `.apply()`. Точно так же вы можете легко [создать условные столбцы в pandas](https://datagy.io/pandas-conditional-column/) различными способами.
* Как суммировать столбцы в Pandas
* [Как рассчитать квантили в Pandas](https://bemind.gitbook.io/uchebniki/uchebniki-po-pandas-i-numpy/pandas/pandas-quantile-raschet-procentilei-v-dataframe)
* Как рассчитать средневзвешенное значение в Pandas
* [Как рассчитать скользящее среднее в Pandas](https://bemind.gitbook.io/uchebniki/uchebniki-po-pandas-i-numpy/pandas/kak-rasschitat-skolzyashee-srednee-srednee-arifmeticheskoe-v-pandas)
* Как рассчитать стандартное отклонение в Pandas
* Как рассчитать медианное абсолютное отклонение в Pandas
* Как рассчитать Z-показатель в Pandas
* Как нормализовать столбец или фрейм данных Pandas
* Как рассчитать дисперсию в Pandas
* Как рассчитать разницу между строками Pandas
* Как рассчитать кросс-таблицы в Pandas
### Сортировка данных и работа с повторяющимися данными
В этом разделе мы рассмотрим, как работать с DataFrame в pandas для сортировки данных и работы с дубликатами данных. Как и следовало ожидать, pandas предлагает значительный функционал для сортировки данных и работы с дубликатами.
#### Как сортировать данные в таблице данных Pandas
Давайте посмотрим, как мы можем использовать метод `.sort_values()` в pandas для сортировки данных в нашем DataFrame. Метод принимает ряд параметров, но давайте сосредоточимся на некоторых из самых важных из них:
* `by=` позволяет передать один метку столбца или список меток столбцов для сортировки по ним
* `ascending=` принимает булево значение, указывающее, следует ли сортировать значения по возрастанию или убыванию
Давайте посмотрим, как мы можем сортировать по колонке `'Продажи'` в нашем DataFrame pandas:
```python
# Sorting Data in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
df = df.sort_values(by='Sales', ascending=False)
print(df.head()
# Date Region Type Units Sales
# 996 2020-12-25 North Men's Clothing NaN 1155.0
# 309 2020-09-11 North Women's Clothing 5.0 1122.0
# 745 2020-12-09 East Children's Clothing 23.0 1122.0
# 222 2020-05-28 South Women's Clothing 13.0 1122.0
# 680 2020-07-03 North Women's Clothing 4.0 1089.0
```
Из приведенного выше блока кода видно, что DataFrame теперь был отсортирован. Если вы внимательно посмотрите, вы также заметите, что DataFrame был переназначен сам себе.
Методы, применяемые к DataFrame, фактически не изменяют сам DataFrame. Мы можем принудительно изменить это поведение во многих методах, передав параметр `inplace=True`. Однако во многих случаях пользователи pandas переназначают DataFrame самому себе.
### Как работать с повторяющимися данными в таблице данных Pandas
Библиотека pandas предоставляет исключительную гибкость при работе с дублирующимися данными, включая возможность идентификации, поиска и удаления дубликатов полей. Библиотека pandas учитывает, что данные могут быть определены как дубликаты, если все столбцы равны, если некоторые столбцы равны, или если любые столбцы равны.
Это позволяет вам обладать значительной гибкостью в отношении поиска и удаления дубликатов записей. Давайте сначала рассмотрим *поиск* дубликатов записей в DataFrame pandas. Это можно сделать с использованием метода `.duplicated()`, который возвращает булев массив:
```python
# Finding Duplicate Records in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.duplicated().head())
# 0 False
# 1 False
# 2 False
# 3 False
# 4 False
```
В данном случае мы вывели на печать первые пять записей полученного объекта Series. Series содержит булевы индикаторы, указывающие, является ли запись по определённому индексу дубликатом или нет.
**По умолчанию** **pandas будет проверять, являются ли все значения в записи дубликатами**. Мы можем проверить наличие дубликатов записей, вычислив сумму этой серии. Поскольку значения `True` считаются за 1, а значения `False` за 0, мы можем получить представление о количестве дубликатов записей таким образом.
```python
# Counting Duplicate Records in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.duplicated().sum())
# Returns: 0
```
В этом случае мы видим, что в нашем DataFrame нет дублирующих записей. **Но что насчет записей, которые дублируются только по подмножеству колонок?** Для этого мы можем использовать параметр `subset=`, который принимает либо метку колонки, либо список меток в качестве входных данных.
Давайте посчитаем, сколько дублирующихся записей существует по столбцам \`\['Type', 'Region']
```python
# Counting Duplicate Records in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.duplicated(subset=['Type', 'Region']).sum())
# Returns: 998
```
В этом случае у нас есть 998 дублирующих записей.
Теперь, когда мы знаем, как подсчитывать дублирующиеся записи, давайте посмотрим, как удалить дублирующиеся записи в pandas DataFrame. Для этого мы можем использовать метод с говорящим названием
Аналогично методу `.duplicated()`, метод `.drop_duplicates()` позволяет выбирать только подмножество столбцов. Однако он также предоставляет возможность использовать следующие дополнительные параметры:
* `subset=` который позволяет вам указать, какие столбцы следует учитывать,
* `keep=` определяет, какую запись сохранить,
* `inplace=` удалит записи на месте, если аргумент установлен в `True`, и
* `ignore_index=`, при установке в значение `True`, сбросит индекс после удаления значений.
Давайте посмотрим, как мы можем использовать метод для удаления дубликатов в столбцах `['Type', 'Region']`:
```python
# Dropping Duplicates in Pandas
# Dropping Duplicate Records in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
df = df.drop_duplicates(subset=['Type', 'Region'])
print(df)
# Returns:
# Date Region Type Units Sales
# 0 2020-07-11 East Children's Clothing 18.0 306.0
# 1 2020-09-23 North Children's Clothing 14.0 448.0
# 2 2020-04-02 South Women's Clothing 17.0 425.0
# 4 2020-03-19 West Women's Clothing 3.0 33.0
# 5 2020-02-05 North Women's Clothing 33.0 627.0
# 7 2020-03-25 East Women's Clothing 29.0 609.0
# 11 2020-08-09 North Men's Clothing NaN 270.0
# 12 2020-05-01 East Men's Clothing 10.0 140.0
# 15 2020-11-26 West Men's Clothing 27.0 864.0
# 30 2020-07-13 West Children's Clothing 30.0 450.0
# 42 2020-03-17 South Children's Clothing 33.0 924.0
# 57 2020-07-23 South Men's Clothing 27.0 351.0
```
В приведенном выше примере наш DataFrame был сокращен всего до двенадцати записей! Возможно, вы задаетесь вопросом, как pandas решил, какие записи оставить, а какие удалить. По умолчанию метод сохранит первый элемент, для которого обнаружены дублирующиеся записи.
Это позволяет вам значительно гибче выбирать, какие записи необходимо удалить. Объединив полученные знания о сортировке значений, вы можете убедиться, что при удалении записей в pandas вы сохраняете наиболее подходящие записи.
Давайте теперь углубимся в другую важную тему: работу с недостающими данными.
### Работа с недостающими данными в Pandas
При работе с отсутствующими данными у вас, как правило, есть два различных варианта:
1. Удалите записи, содержащие отсутствующие данные, или
2. Заполните отсутствующие данные определенным значением.
Вы, возможно, помните, что ранее, когда мы использовали метод `.info()`, мы могли увидеть, сколько непустых записей существует в каждом столбце. Давайте ещё раз на это посмотрим:
```python
# Using the .info() Method to Display Information
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.info())
# Returns:
#
# RangeIndex: 1000 entries, 0 to 999
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Date 1000 non-null object
# 1 Region 1000 non-null object
# 2 Type 1000 non-null object
# 3 Units 911 non-null float64
# 4 Sales 1000 non-null float64
# dtypes: float64(2), object(3)
# memory usage: 39.2+ KB
```
Проведя дополнительные расчеты, мы увидели, что в столбце "Единицы" отсутствует 89 записей. В данном случае это было просто подсчитать. Однако, работая с разными наборами данных, это может стать немного сложнее (не говоря уже о том, как это может раздражать).
Мы можем упростить этот процесс, используя метод `.isna()` библиотеки pandas, и подсчитать сумму возвращаемого им булевого DataFrame с помощью метода `.sum()`. Давайте посмотрим, как это выглядит:
```python
# Counting Missing Records in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
print(df.isna().sum())
# Returns:
# Date 0
# Region 0
# Type 0
# Units 89
# Sales 0
# dtype: int64
```
Теперь, когда мы научились подсчитывать отсутствующие записи, давайте перейдем к работе с этими отсутствующими данными. Мы исследуем как удаление, так и заполнение отсутствующих данных, но для начала давайте рассмотрим, как удалить отсутствующие данные из набора данных в pandas.
#### Как удалить недостающие данные в Pandas
Метод `.dropna()` библиотеки Pandas является необходимым инструментом для аналитика данных или научного сотрудника любого уровня. Поскольку очистка данных является важным этапом предварительной обработки, умение работать с отсутствующими данными сделает вас лучшим программистом.
Прежде чем углубиться в использование этого метода, давайте потратим минуту на то, чтобы понять, как работает метод Pandas `.dropna()`. Мы можем сделать это, взглянув на параметры и аргументы по умолчанию, которые предоставляет метод:
```python
# Understanding the Pandas .dropna() Method
import pandas as pd
df = pd.DataFrame()
df.dropna(
axis=0,
how='any',
thresh=None,
subset=None,
inplace=False
)
```
Метод `dropna()` в Pandas облегчает удаление всех строк с отсутствующими данными. По умолчанию метод `dropna()` будет удалять любую строку с каким-либо отсутствующим значением. Это связано с тем, что параметр `how=` установлен в `'any'` и параметр `axis=` установлен в `0`.
Посмотрим, что произойдет, когда мы удалим пропущенные данные из нашего DataFrame:
```python
# Dropping Duplicate Records in a Pandas DataFrame
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
df = df.dropna()
print(df.isna().sum())
# Returns:
# Date 0
# Region 0
# Type 0
# Units 0
# Sales 0
# dtype: int64
```
Мы видим, что применение метода `.dropna()` к DataFrame привело к удалению любой записи, содержащей пропущенное значение. Метод `.dropna()` в pandas предоставляет значительную гибкость в как удалять записи с отсутствующими данными, например, позволяя убедиться, что должны отсутствовать определенные столбцы.
Теперь давайте изучим, как заполнять пропущенные данные в pandas.
#### Как заполнить недостающие данные в Pandas
Метод `.fillna()` в pandas используется для заполнения пропущенных значений определенным значением в DataFrame. Этот метод позволяет передать значение для заполнения отсутствующих записей. Давайте посмотрим, как мы можем заполнить пропущенные значения в колонке `'Units'` значением 0.
```python
# Filling Missing Data in a Column
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
df = df.sort_values(by='Units')
df['Units'] = df['Units'].fillna(0)
print(df)
# Returns:
# Date Region Type Units Sales
# 141 2020-02-12 East Women's Clothing 3.0 330.0
# 28 2020-01-19 East Men's Clothing 3.0 63.0
# 686 2020-02-18 West Men's Clothing 3.0 918.0
# 310 2020-02-25 East Men's Clothing 3.0 330.0
# 684 2020-04-08 East Men's Clothing 3.0 806.0
# .. ... ... ... ... ...
# 927 2020-02-24 North Men's Clothing 0.0 210.0
# 939 2020-02-26 North Men's Clothing 0.0 300.0
# 945 2020-04-12 North Men's Clothing 0.0 364.0
# 946 2020-01-30 North Men's Clothing 0.0 285.0
# 996 2020-12-25 North Men's Clothing 0.0 1155.0
# [1000 rows x 5 columns]
```
В приведенном выше примере мы видим, что все отсутствующие данные были заполнены значением 0. Обратите внимание, мы отсортировали DataFrame таким образом, чтобы отсутствующие данные находились в конце DataFrame. Аналогично, вы можете указать pandas заполнить отсутствующие данные другим рассчитанным значением, таким как среднее значение по столбцу. Это можно сделать, передав в метод `.fillna()` значение
Этот метод предоставляет значительно больше гибкости, например, возможность заполнения пропущенных данных в обратном порядке или прямом порядке, что может быть невероятно полезно при работе с временными рядами.
### Сводные таблицы Pandas и изменение формы данных
Сводная таблица — это таблица статистики, которая помогает суммировать данные большой таблицы за счет "поворота" этих данных. Microsoft Excel популяризировал сводные таблицы, где они известны как PivotTables. Pandas предоставляет возможность создавать сводные таблицы в Python с использованием функции `.pivot_table()`. У функции есть следующие параметры по умолчанию:
```python
# The syntax of the .pivot_table() function
import pandas as pd
pd.pivot_table(
data=,
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All',
observed=False,
sort=True
)
```
Создаем вашу первую сводную таблицу Pandas. Как минимум, нам необходимо передать некий ключ группировки, используя параметры `index=` или `columns=`. В приведенных ниже примерах мы используем функцию Pandas, а не метод DataFrame. Поэтому нам нужно передать аргумент `data=`. Если бы мы применили метод непосредственно к DataFrame, это было бы подразумеваемо.
```python
# Creating your first Pandas pivot table
pivot = pd.pivot_table(
data=df,
index='Region'
)
print(pivot)
# Returns:
# Sales Units
# Region
# East 408.182482 19.732360
# North 438.924051 19.202643
# South 432.956204 20.423358
# West 452.029412 19.29411
```
Давайте разберем, что здесь произошло:
1. Мы создали новый DataFrame под названием `sales_by_region`, который был создан с использованием функции
2. Мы передали наш DataFrame, `df`, и установили `index='region'`, что означает группировку данных по столбцу региона.
Поскольку все остальные параметры были оставлены по умолчанию, Pandas сделало следующее предположение:
* Данные должны быть агрегированы по среднему значению каждого столбца (`aggfunc='mean'`)
* Значения должны быть любыми числовыми столбцами
При добавлении столбцов к сводной таблице Pandas мы добавляем еще одно измерение к данным. В то время как параметр `index=` разделяет данные вертикально, параметр `columns=` группирует и разделяет данные горизонтально. Это позволяет нам создать легко читаемую таблицу. Давайте посмотрим, как мы можем использовать параметр `columns=` для разделения данных по столбцу Type.
```python
# Adding Columns to Our Pandas Pivot Table
pivot = pd.pivot_table(
data=df,
index='Region',
columns='Type',
values='Sales'
)
print(pivot)
# Returns:
# Type Children's Clothing Men's Clothing Women's Clothing
# Region
# East 405.743363 423.647541 399.028409
# North 438.894118 449.157303 432.528169
# South 412.666667 475.435897 418.924528
# West 480.523810 465.292683 419.188679
```
Мы видим, насколько легко было добавить совершенно новое измерение данных. Это позволяет нам замечать различия между группировками в формате, который легко читать.
Pivot-таблицы в pandas предоставляют невероятную универсальность и гибкость в анализе данных в pandas. Вы также можете изменять структуру данных с помощью функции melt, которая позволяет преобразовать широкие наборы данных в длинные. Аналогичным образом, вы можете легко транспонировать DataFrame в pandas с помощью встроенных и интуитивно понятных методов.
### Группировка данных с помощью Pandas Group By
Метод `.groupby()` в Pandas работает очень похожим образом на инструкцию `GROUP BY` в SQL. Фактически, он разработан, чтобы отражать его SQL-аналог, используя его эффективность и интуитивность. Подобно инструкции `GROUP BY` в SQL, метод в Pandas работает путем разделения наших данных, их агрегирования определенным образом (или несколькими способами) и повторного объединения данных в значимом виде.
Поскольку метод `.groupby()` работает, сначала разделяя данные, мы можем напрямую работать с группами. Аналогично, поскольку любая агрегация выполняется после разделения, у нас есть полная свобода действий в отношении способа агрегирования данных. Затем Pandas обрабатывает объединение данных таким образом, чтобы представить значимый DataFrame.
Метод groupby в Pandas использует процесс, известный как разделение, применение и объединение, чтобы предоставить полезные агрегации или модификации вашему DataFrame. Этот процесс работает именно так, как называется:
1. **Разделение** данных на группы по определенным критериям
2. **Применение** функции к каждой группе независимо
3. **Комбинирование** результатов в соответствующую структуру данных
В приведенном выше разделе, когда вы использовали метод `.groupby()` и передали в него столбец, вы уже завершили первый шаг! Вы смогли разделить данные на соответствующие группы на основе критерия, который передали.
Применение этого метода позволяет разбить большую задачу анализа данных на управляемые части. Это позволяет выполнять операции с отдельными частями и собирать их вместе. Хотя шаги **применения** и **объединения** выполняются отдельно, Pandas абстрагирует это и создает видимость, будто это был один шаг.
Давайте рассмотрим, как мы можем использовать метод `.groupby()` в pandas для агрегирования данных в разные группы.
```python
# Using the .groupby() Method to Aggregate Data
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv')
aggregate = df.groupby('Region')['Sales'].mean()
print(aggregate)
# Returns:
# Region
# East 408.182482
# North 438.924051
# South 432.956204
# West 452.029412
# Name: Sales, dtype: float64
```
Мы видим, что метод может быть использован для группировки данных различными способами. После группировки данных их можно агрегировать различными методами. В приведенном выше примере мы использовали метод `.mean()` для агрегации данных о продажах, разделенных по регионам.
Чтобы узнать больше о методе `.groupby()` в Pandas, ознакомьтесь с этим подробным руководством по агрегированию данных в Pandas. Также ознакомьтесь с другими ресурсами ниже, чтобы узнать о различных способах использования метода:
* Pandas Groupby и агрегат для нескольких столбцов
* Pandas: подсчет уникальных значений в объекте GroupBy
### Работа с датами в Pandas
В этом разделе мы рассмотрим одну из по-настоящему потрясающих функций библиотеки pandas: работу с датами. Одно из интересных вещей, которое мы исследуем здесь, заключается в том, что когда мы загружаем наши данные до сих пор, они на самом деле просто загружаются как строки. pandas представляет их как тип данных `'object'`. Мы можем изменить это поведение, когда читаем наш CSV-файл в DataFrame. Давайте посмотрим, как это выглядит:
```python
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv', parse_dates=['Date'])
print(df.info())
# Returns:
#
# RangeIndex: 1000 entries, 0 to 999
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Date 1000 non-null datetime64[ns]
# 1 Region 1000 non-null object
# 2 Type 1000 non-null object
# 3 Units 911 non-null float64
# 4 Sales 1000 non-null float64
# dtypes: datetime64[ns](1), float64(2), object(2)
# memory usage: 39.2+ KB
# None
```
В приведенном выше примере мы добавили дополнительный параметр при загрузке нашего набора данных: параметр `parse_dates=`. Это позволяет передать список меток столбцов для чтения в качестве дат. Теперь, когда мы проверяем типы данных с помощью метода `.info()`, наш столбец действительно имеет тип данных datetime.
Это теперь предоставляет вам доступ ко всему подмножеству атрибутов и функций даты и времени. Например, мы можем получить доступ к месяцу и году заданной даты, используя атрибуты `.dt.month` и `.dt.year` столбца datetime. Давайте посмотрим, как это выглядит:
```python
# Parsing Out Date Attributes in Pandas
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv', parse_dates=['Date'])
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
print(df.head())
# Returns:
# Date Region Type Units Sales Year Month
# 0 2020-07-11 East Children's Clothing 18.0 306.0 2020 7
# 1 2020-09-23 North Children's Clothing 14.0 448.0 2020 9
# 2 2020-04-02 South Women's Clothing 17.0 425.0 2020 4
# 3 2020-02-28 East Children's Clothing 26.0 832.0 2020 2
# 4 2020-03-19 West Women's Clothing 3.0 33.0 2020 3
```
Точно так же pandas умеет использовать логические операторы для фильтрации дат! Мы можем просто использовать операторы больше или меньше для фильтрации DataFrame на основе их дат. Давайте посмотрим, как это выглядит:
```python
# Filtering a Pandas DataFrame Based on Dates
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/data.csv', parse_dates=['Date'])
print(df[df['Date'] > '2020-12-01'].head())
# Returns:
# Date Region Type Units Sales
# 32 2020-12-20 East Women's Clothing 30.0 930.0
# 35 2020-12-17 West Children's Clothing 25.0 575.0
# 38 2020-12-30 North Children's Clothing 26.0 390.0
# 58 2020-12-25 East Men's Clothing 13.0 403.0
# 81 2020-12-11 South Women's Clothing 13.0 429.0
```
Мы видим, что, передав логический оператор в операцию фильтрации, pandas отфильтровал наш DataFrame до определённого диапазона дат.
Чтобы узнать больше о работе с датами в pandas и Python, ознакомьтесь с ресурсами ниже:
* Как использовать DateTime в Pandas и Python
* Как использовать Pandas Datetime для доступа к частям даты (месяц, год и т. д.)
* Как использовать Python для преобразования строки в дату
* Как использовать Python для преобразования даты в строку
* Как создать диапазоны дат с помощью Pandas
* Как получить финансовый год с Pandas
* Pandas to\_datetime: преобразование строкового столбца Pandas в дату и время
* Как добавить дни в столбец даты в Pandas
### Объединение данных с Pandas
Существует несколько различных способов объединения данных. Например, вы можете объединить наборы данных, добавляя их друг к другу. Этот процесс включает в себя объединение наборов данных путем расположения строк одного набора данных под строками другого. Этот процесс будет называться **конкатенацией** или **добавлением** наборов данных.
Существует несколько способов объединения наборов данных. Например, вы можете требовать, чтобы все наборы данных имели одинаковые колонки. С другой стороны, вы можете выбрать включение несоответствующих колонок, тем самым внося потенциал для включения отсутствующих данных.
Обычно **процесс конкатенации наборов данных приведет к увеличению длины набора данных, а не его ширины**. Однако, если вы готовы добавлять наборы данных с несовпадающими столбцами, результирующий набор данных также может увеличиться в ширину. Конкатенация наборов данных сосредоточена на объединении на основе столбцов, а не на основе записей. Это обобщение и не всегда является верным!
Вы также можете **объединять** наборы данных, чтобы получить более крупный. В этом руководстве такой процесс будет называться либо объединением, либо слиянием наборов данных. Когда вы объединяете один набор данных с другим, вы сливаете эти наборы на основе ключа (или ключей).
В целом, **процесс объединения наборов данных сосредотачивается на увеличении ширины набора данных, а не его длины**. В зависимости от общих отношений между записями, а также от выбранного метода объединения, количество строк также может увеличиться. Объединение наборов данных сосредоточено на слиянии на основе значений записей, а не на основе заголовков столбцов.
#### Добавление фреймов данных Pandas с помощью .concat()
Для того чтобы следовать за этим разделом, давайте загрузим несколько DataFrame для лучшего понимания нюансов некоторых способов объединения DataFrame в Pandas. Мы загрузим три различных DataFrame с некоторым перекрытием:
```python
# Loading Sample Pandas DataFrames
import pandas as pd
df1 = pd.DataFrame.from_dict({'col1': [1, 2, 3], 'col2': ['a', 'b', 'c'], 'col3': ['a1', 'b2', 'c3']})
df2 = pd.DataFrame.from_dict({'col1': [4, 5, 6], 'col2': ['d', 'e', 'f'], 'col3': ['d4', 'e5', 'f6']})
df3 = pd.DataFrame.from_dict({'col1': [7, 8, 9], 'col2': ['g', 'h', 'i'], 'col4': ['g7', 'h2', 'i3']})
print('df1 looks like:')
print(df1)
print('\ndf2 looks like:')
print(df2)
print('\ndf3 looks like:')
print(df3)
# Returns:
# df1 looks like:
# col1 col2 col3
# 0 1 a a1
# 1 2 b b2
# 2 3 c c3
# df2 looks like:
# col1 col2 col3
# 0 4 d d4
# 1 5 e e5
# 2 6 f f6
# df3 looks like:
# col1 col2 col4
# 0 7 g g7
# 1 8 h h2
# 2 9 i i3
```
Давайте начнем с самого простого примера: конкатенация двух DataFrame с одинаковыми столбцами. Функция `concat()` из pandas может быть использована для добавления одного DataFrame к другому. Для этого достаточно передать в нее объекты, которые вы хотите объединить, просто передав список объектов. В данном случае мы можем передать `[df1, df2]`. Давайте посмотрим, к чему это приведет:
```python
# Concatenating simple DataFrames
df_concat = pd.concat([df1, df2])
print(df_concat)
# Returns:
# col1 col2 col3
# 0 1 a a1
# 1 2 b b2
# 2 3 c c3
# 0 4 d d4
# 1 5 e e5
# 2 6 f f6
```
#### Объединение фреймов данных Pandas с использованием .merge()
Pandas обеспечивает большую гибкость при выполнении операций объединения, подобных работе с базами данных. Хотя на первый взгляд функция работает довольно элегантно, под капотом скрывается множество возможностей. Например, вы можете выполнить множество различных типов слияний (таких как внутреннее, внешнее, левостороннее и правостороннее) и объединять данные по одному ключу или нескольким ключам.
Для того, чтобы следовать за этим уроком, давайте загрузим три простых DataFrame. Просто скопируйте код ниже, чтобы загрузить эти DataFrame и лучше следить за этой частью урока:
```python
# Loading Sample DataFrames
books = pd.DataFrame.from_dict({
'Author ID': [1,1,2,3],
'Book ID': [1,2,1,1],
'Name': ['Intro to Python', 'Python 201', 'Data Science', 'Machine Learning']})
authors = pd.DataFrame.from_dict({
'Author ID': [1,2,3,4],
'Name': ['Nik', 'Kate', 'Jane', 'Evan']})
sales = pd.DataFrame.from_dict({
'Author ID': [1,1,1,2,3,4],
'Book ID': [1,2,1,1,1,1],
'Sales': [10, 20, 10, 30, 45, 10]})
print('DataFrame books looks like:')
print(books.head(2))
print('\nDataFrame authors looks like:')
print(authors.head(2))
print('\nDataFrame sales looks like:')
print(sales.head(2))
# Returns:
# Author ID Book ID Name
# 0 1 1 Intro to Python
# 1 1 2 Python 201
# DataFrame authors looks like:
# Author ID Name
# 0 1 Nik
# 1 2 Kate
# DataFrame sales looks like:
# Author ID Book ID Sales
# 0 1 1 10
# 1 1 2 20
```
Давайте теперь рассмотрим, как мы можем легко объединять данные в Pandas.
Простейший тип слияния данных, который мы можем выполнить, — это слияние по одному столбцу. Давайте посмотрим, как мы можем осуществить слияние DataFrame `books` и DataFrame `authors`. Чтобы получить имя автора, мы объединяем DataFrames на основе идентификатора автора. Давайте посмотрим, как это можно сделать, используя в основном аргументы по умолчанию.
```python
# Merging DataFrames based on a Single Column
merged = pd.merge(
left=books,
right=authors,
left_on='Author ID',
right_on='Author ID'
)
print(merged)
# Returns:
# Author ID Book ID Name_x Author ID Name_y
# 0 1 1 Intro to Python 1 Nik
# 1 1 2 Python 201 1 Nik
# 2 2 1 Data Science 2 Kate
# 3 3 1 Machine Learning 3 Jane
```
По умолчанию Pandas выполняет внутреннее соединение. Это означает, что в результирующий набор данных будут включены только те записи, для которых ключ `left_on` и ключ `right_on` существуют в обоих наборах данных. Из-за этого автор с идентификатором 4 не будет включен в объединенный набор данных.
Чтобы узнать больше о том, как добавлять и объединять DataFrames в pandas, ознакомьтесь с этим [полным руководством по объединению наборов данных в pandas](https://datagy.io/pandas-merge-concat/)
### Что дальше?
Pandas - это библиотека для анализа данных в Python, которая предоставляет бесконечные возможности для анализа ваших данных. Библиотека упрощает работу с табличными данными, предоставляя знакомый интерфейс, который будет полезен как начинающим программистам, так и опытным профессионалам.
Лучший способ изучить библиотеку - это начать её использовать. Ссылки на учебные материалы в этом руководстве предоставляют вам отличные отправные точки. Однако, я рекомендую использовать их как ресурсы при возникновении проблем в ваших проектах.