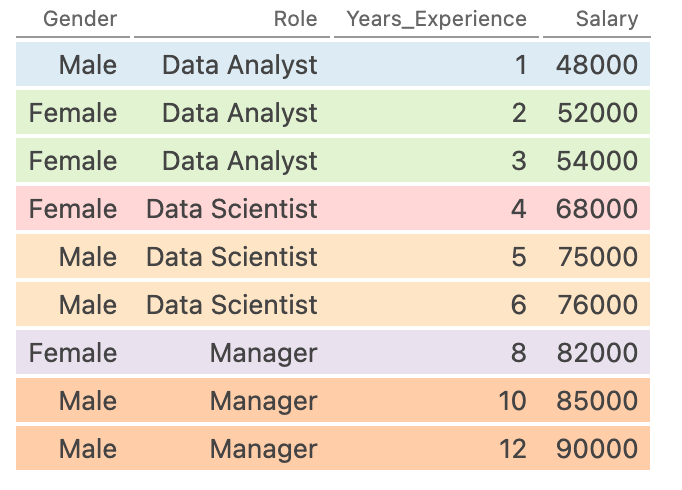
Понимание группировки по нескольким столбцам в Pandas
Понимание группировки по нескольким столбцам в Pandas

Как агрегировать данные по нескольким столбцам в Pandas

Применение нескольких агрегатов к Pandas GroupBy с несколькими столбцами
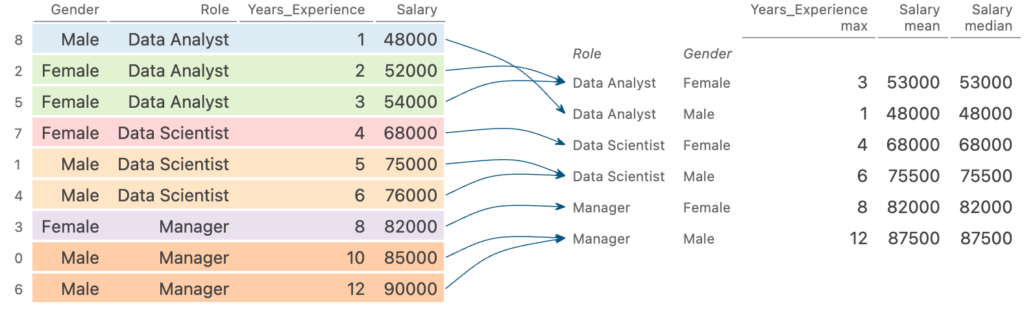
Группировка по нескольким столбцам и объединение разных столбцов