
Pandas to_excel: Запись DataFrames в файлы Excel
В этом руководстве вы научитесь сохранять ваши DataFrame или DataFrames Pandas в файлы Excel. Умение сохранять данные в этом всемирно распространенном формате данных является важным навыком во многих организациях. В этом руководстве вы научитесь сохранять простой DataFrame в Excel, а также настроить ваши параметры, чтобы создать отчет, который вы хотите!
К концу этого руководства вы узнаете:
Как сохранить DataFrame Pandas в Excel
Как настроить имя листа вашего DataFrame в Excel
Как настроить имена индексов и столбцов при записи в Excel
Как написать несколько DataFrames в Excel в Pandas
Следует ли объединять ячейки или замораживать панели при записи в Excel в Pandas.
Как форматировать пропущенные значения и значения бесконечности при написании Pandas в Excel
Оглавление
Быстрый ответ: используйте Pandas to_excel
Чтобы записать DataFrame Pandas в файл Excel, вы можете использовать метод .to_excel(), применяемый к DataFrame, как показано ниже:
Понимание функции Pandas to_excel
Перед тем, как погрузиться в какие-либо конкретные детали, давайте рассмотрим различные параметры, которые предлагает метод. Метод предоставляет множество различных опций, позволяя вам настраивать вывод вашего DataFrame множеством различных способов. Давайте рассмотрим:
Давайте разберем, что делает каждый из этих параметров:
excel_writer=
Путь к ExcelWriter, который будет использоваться.
path-like, file-like, or ExcelWriter object
sheet_name=
Имя используемого листа
Строка, представляющая имя, по умолчанию ‘Sheet1’
na_rep=
Как представить недостающие данные
Строка, по умолчаниюt ''
float_format=
Позволяет передавать строку формата для форматирования значений с плавающей запятой.
Строка
columns=
Столбцы, которые будут использоваться при записи в файл
Список строк. Если пусто, будет написано все
header=
Принимает либо логическое значение, либо список значений. Если логическое значение, заголовок будет либо включен, либо нет. Если указан список значений, для имен столбцов будут использоваться псевдонимы.
Логическое значение или список значений
index=
Включить ли индексный столбец или нет.
логическое значение
index_label=
Метки столбцов, используемые для индекса.
Строка или список строк.
startrow=
Верхняя левая ячейка для запуска DataFrame.
Целое число, по умолчанию 0
startcol=
Верхний левый столбец для запуска DataFrame.
Целое число, по умолчанию 0
engine=
Движок, используемый для записи.
openpyxl or xlsxwriter
merge_cells=
Записывать ли многоиндексные ячейки или иерархические строки как объединенные ячейки
Boolean, default True
encoding=
Кодировка полученного файла.
Строка
inf_rep=
Как представлять значения бесконечности (поскольку в Excel нет представления)
Строка, по умолчанию 'inf'
verbose=
Отображать ли дополнительную информацию в журналах ошибок.
Логическое значение, по умолчанию True
freeze_panes=
Позволяет передать кортеж строки и столбца, чтобы начать замораживание панелей.
Кортеж целых чисел длиной 2
storage_options=
Дополнительные параметры, которые позволяют сохранять данные в конкретном подключении к хранилищу.
Словарь
Как сохранить фрейм данных Pandas в Excel
Самый простой способ сохранить DataFrame Pandas в файл Excel — это передать путь методу .to_excel(). Это сохранит DataFrame в файл Excel по этому пути, заменив существующий файл Excel, если он уже существует.
Давайте посмотрим, как это работает:
Выполнение кода как показано выше сохранит файл со всеми другими параметрами по умолчанию. Это возвращает следующее изображение:
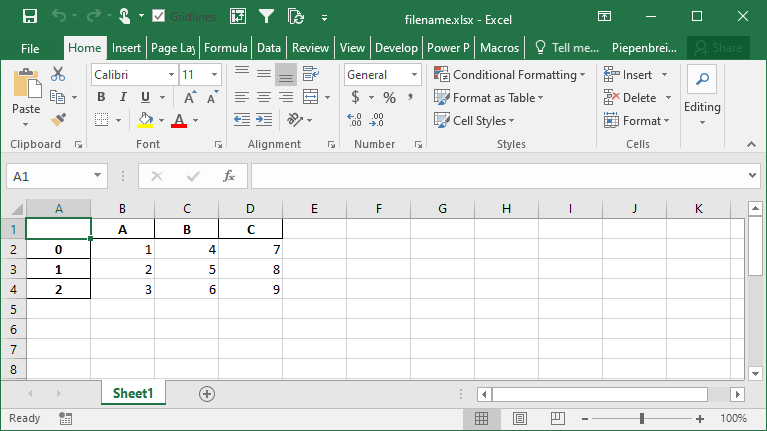
Вы можете указать имя листа, используя параметр sheet_name=. По умолчанию Pandas будет использовать 'sheet1'.
Это возвращает следующую рабочую книгу:
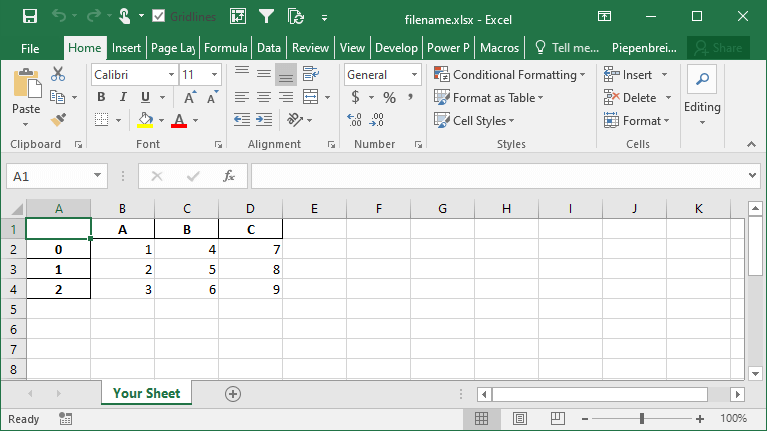
В следующем разделе вы узнаете, как настроить включение или исключение индексного столбца.
Как включить индекс при сохранении фрейма данных Pandas в Excel
По умолчанию Pandas будет включать индекс при сохранении DataFrame Pandas в файл Excel. Это может быть полезно, когда индекс имеет особое значение (такое как дата и время). Однако во многих случаях индекс просто будет представлять значения от 0 до конца записей.
Если вы не хотите включать индекс в свой файл Excel, вы можете использовать параметр index=, как показано ниже:
Это возвращает следующий файл Excel:
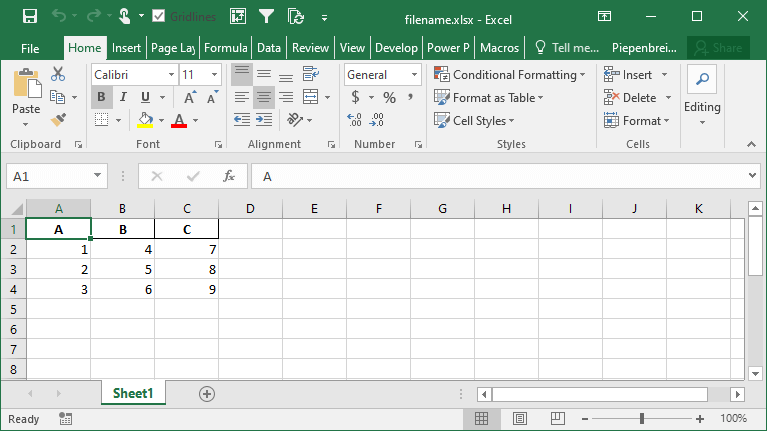
В следующем разделе вы узнаете, как переименовать индекс при сохранении DataFrame Pandas в файл Excel.
Как переименовать индекс при сохранении фрейма данных Pandas в Excel
По умолчанию Pandas не присваивает названия индексам вашего DataFrame. Это может привести к путанице и ухудшению результатов при попытке манипулировать данными в Excel, будь то фильтрация или создание сводных таблиц. Из-за этого может быть полезным задать имя или имена для ваших индексов.
Pandas упрощает этот процесс с помощью параметра index_label=. Данный параметр принимает одну строку (для одного индекса) или список строк (для мульти-индекса). Смотрите ниже, как вы можете использовать этот параметр:
Это возвращает следующий лист:
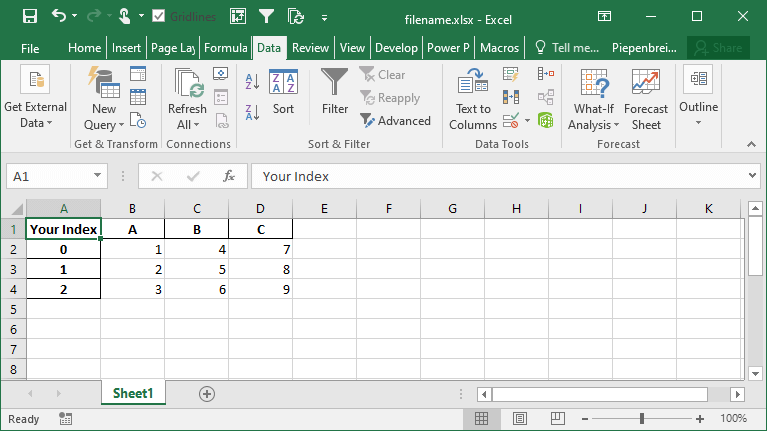
Как сохранить несколько фреймов данных на разных листах в Excel
Одна из задач, с которой вы можете столкнуться довольно часто, заключается в необходимости сохранить несколько DataFrame Pandas в одном файле Excel, но на разных листах. В этом случае Pandas делает процесс менее интуитивно понятным. Если вы просто выполните следующий код, вторая команда перезапишет первую команду:
Вместо этого нам нужно использовать Excel Writer библиотеки Pandas для управления открытием и сохранением нашей книги. Это можно легко сделать, используя менеджер контекста, как показано ниже:
Это приведет к созданию нескольких листов в одной и той же книге. Листы будут созданы в том же порядке, в котором вы указываете их в команде выше.
Это возвращает следующую рабочую книгу:
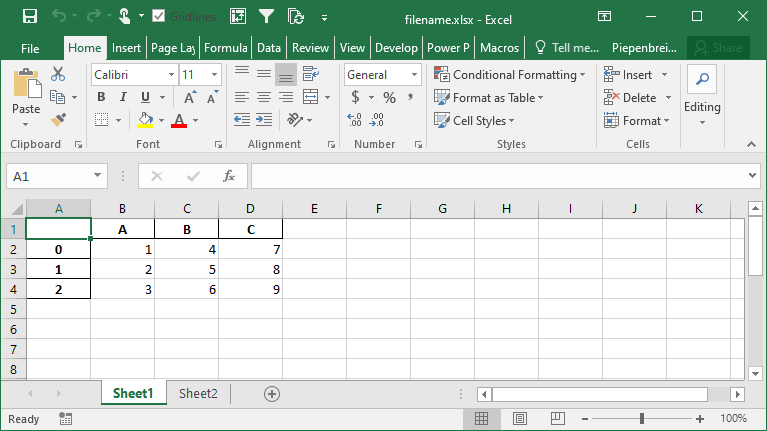
Как сохранить только некоторые столбцы при экспорте фреймов данных Pandas в Excel
При сохранении DataFrame в файл Excel не всегда необходимо сохранять все столбцы. Часто файл Excel используется для отчетности, и сохранение всех столбцов может быть избыточным. Для этого можно использовать параметр columns=, чтобы сохранить только необходимые столбцы.
Давайте посмотрим, как мы можем сохранить только несколько столбцов из нашего набора данных:
Перевести на русский язык
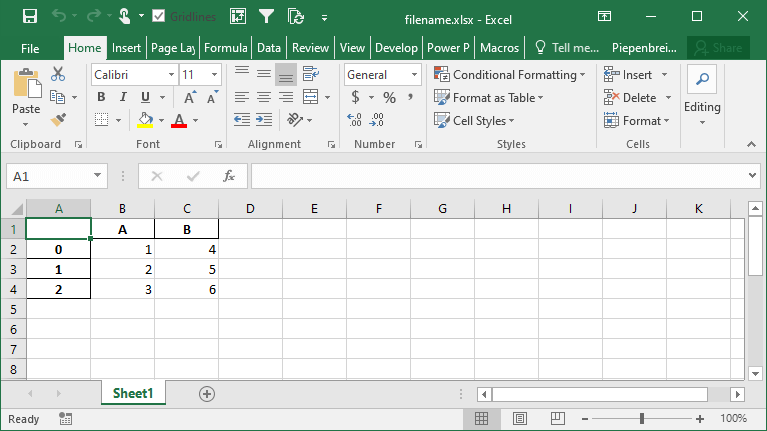
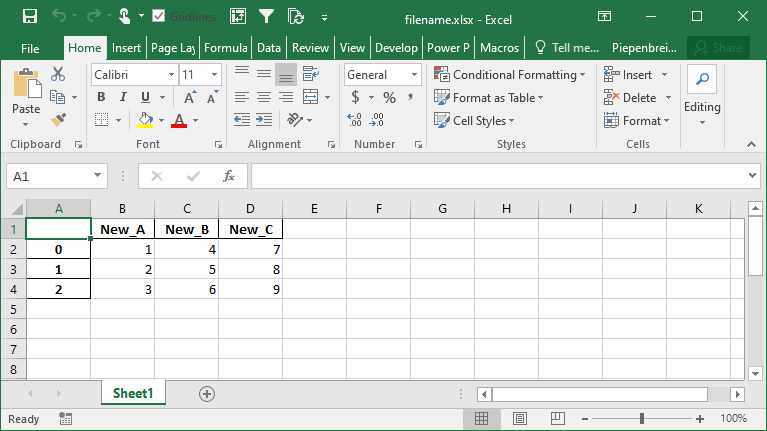
Как переименовать столбцы при экспорте фреймов данных Pandas в Excel
Продолжая наш разговор о том, как управлять столбцами DataFrame в Pandas при экспорте в Excel, мы также можем переименовать наши столбцы в сохраненном файле Excel. Преимущество этого в том, что мы можем работать с псевдонимами в Pandas, которые могут быть легче для написания, но затем выводить готовые для презентации имена столбцов при сохранении в Excel.
Это можно выполнить, используя параметр header=. Данный параметр принимает либо булево значение, либо список значений. Если передается булево значение, вы можете решить, включать ли заголовок или нет. Когда предоставляется список строк, тогда вы можете изменить названия столбцов в получаемом файле Excel, как показано ниже:
Это возвращает следующий лист в Excel:
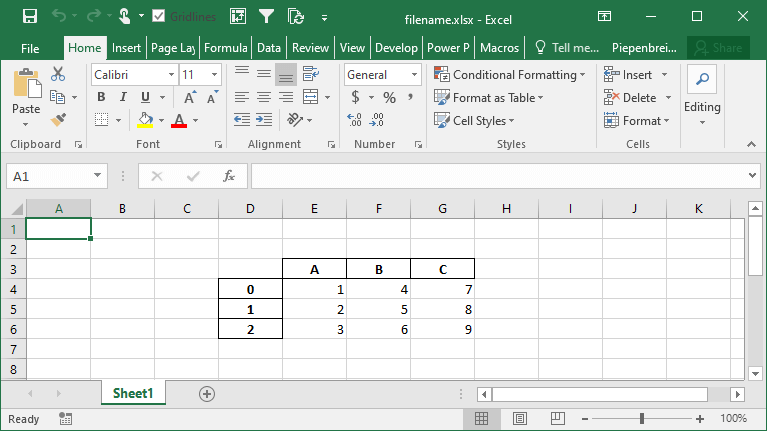
Как указать начальные позиции при экспорте фрейма данных Pandas в Excel
Одной из интересных функций, которую предоставляет Pandas, является возможность изменения начальной позиции сохранения вашего DataFrame на листе Excel. Это может быть полезно, если вы планируете добавить различные строки над вашими данными или логотип вашей компании.
Давайте посмотрим, как мы можем использовать параметры startrow= и startcol=, чтобы изменить это:
Это возвращает следующий рабочий лист:
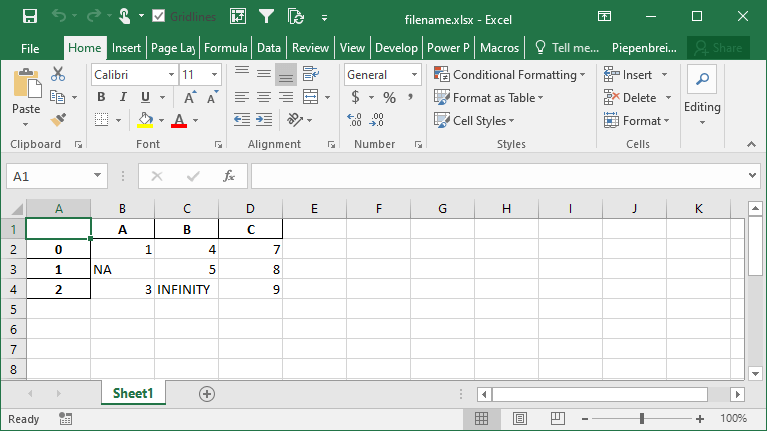
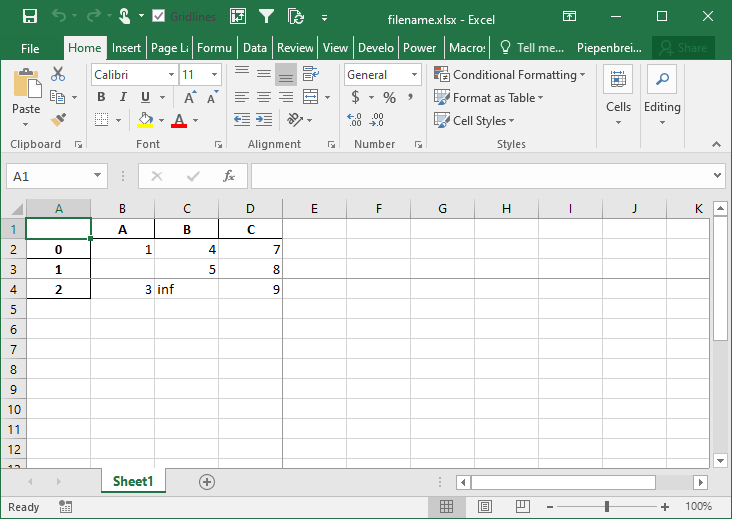
Как представить отсутствующие и бесконечные значения при сохранении фрейма данных Pandas в Excel
В этом разделе вы узнаете, как представлять отсутствующие данные и значения бесконечности при сохранении DataFrame Pandas в Excel. Поскольку Excel не имеет способа представления бесконечности, Pandas по умолчанию использует строку 'inf', чтобы представить любые значения бесконечности.
Чтобы изменить эти поведения, мы можем использовать параметры na_rep= и inf_rep=, чтобы изменить представление отсутствующих значений и значений бесконечности соответственно. Давайте посмотрим, как мы можем сделать это, добавив некоторые из этих значений в наш DataFrame:
Это возвращает следующий рабочий лист:
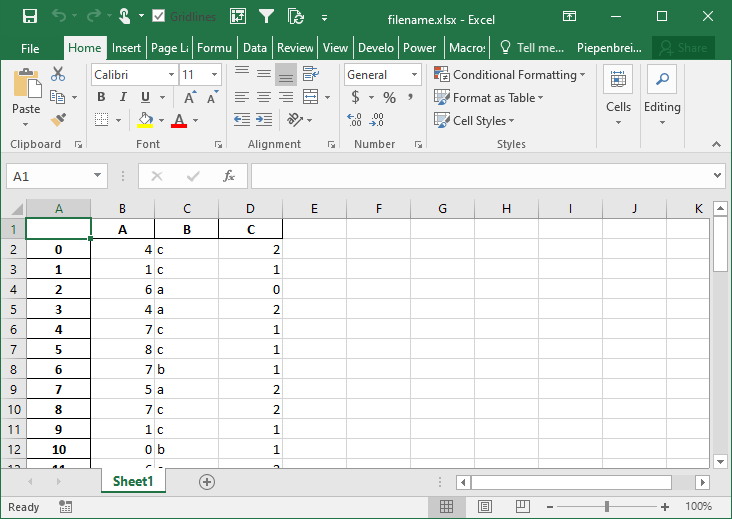
Как объединить ячейки при записи многоиндексных фреймов данных в Excel
В этом разделе вы узнаете, как изменить поведение многоуровневых DataFrame при сохранении их в Excel. По умолчанию Pandas устанавливает параметр merge_cells= в значение True, что означает слияние ячеек. Давайте посмотрим, что произойдет, если мы установим это поведение в False, указывая, что ячейки объединяться не должны.
Это возвращает таблицу Excel ниже:
Как закрепить панели при сохранении фрейма данных Pandas в Excel
В этом заключительном разделе вы узнаете, как заморозить области в вашем итоговом рабочем листе Excel. Это позволяет вам указать строку и столбец, на которых вы хотите заморозить панели. Это можно сделать с использованием параметра freeze_panes=. Параметр принимает кортеж из целых чисел (длиной 2). Кортеж представляет собой самую нижнюю строку и самый правый столбец, которые должны быть заморожены.
Давайте посмотрим, как мы можем использовать параметр freeze_panes=, чтобы "заморозить" области в Excel:
Это возвращает следующую рабочую книгу:
Заключение
В этом учебном пособии вы научились сохранять DataFrame Pandas в файл Excel с помощью метода to_excel. Сначала вы изучили все различные параметры, которые предлагала функция, на высоком уровне. Затем вы научились использовать эти параметры, чтобы контролировать, как должен быть сохранен результирующий файл Excel. Например, вы узнали, как указать названия листов, названия индексов и включать ли индекс. Далее вы научились включать в результирующий файл только некоторые столбцы и как переименовать столбцы вашего DataFrame. Вы также узнали, как изменить начальное положение данных и как заморозить области.
Дополнительные ресурсы
Чтобы узнать больше о связанных темах, ознакомьтесь с обучающими материалами ниже:
Как использовать Pandas для чтения файлов Excel на Python
Таблица данных Pandas в файл CSV – экспорт с использованием .to_csv()
Введение в Pandas для науки о данных
Последнее обновление