
Объяснение группировки по нескольким столбцам в Pandas с примерами
Метод groupby в Pandas является мощным инструментом, который позволяет агрегировать данные с использованием простого синтаксиса, при этом абстрагируясь от сложных вычислений. Одним из главных преимуществ метода groupby является возможность группировки по нескольким столбцам и применения нескольких трансформаций.
К концу этого руководства вы научитесь следующему:
Как использовать метод Pandas groupby с несколькими столбцами, ознакомившись с синтаксисом и практическими примерами.
Как использовать несколько агрегатов для нескольких столбцов, что позволяет рассчитывать сводную статистику для нескольких столбцов.
Как указать, какие агрегаты использовать для разных столбцов с помощью группы Pandas.
Как настроить поведение группы Pandas путем переименования столбцов, обработки пропущенных значений и использования пользовательских функций.
Быстрый Ответ: Как Использовать Метод GroupBy в Pandas с Несколькими Колонками
Как вы можете использовать метод Pandas groupby с несколькими столбцами?
Чтобы использовать метод groupby в Pandas с несколькими столбцами, вы можете передать список заголовков столбцов непосредственно в метод. Порядок, в котором вы добавляете столбцы в список, определяет иерархию столбцов, которые вы используете.
Оглавление
Загрузка образца DataFrame Pandas
В этом руководстве мы будем использовать простой DataFrame от Pandas, который позволит нам легко разобраться, как работает группировка по нескольким столбцам, используя метод groupby от Pandas:
Распечатав этот DataFrame, мы возвращаем следующую таблицу:
Male
Data Analyst
1
48000
Female
Data Analyst
2
52000
Female
Data Analyst
3
54000
Female
Data Scientist
4
68000
Male
Data Scientist
5
75000
Male
Data Scientist
6
76000
Female
Manager
8
82000
Male
Manager
10
85000
Male
Manager
12
90000
Мы видим, что в нашем DataFrame есть четыре столбца:
Пол нашего сотрудника
Годы Опыта Работы, показывающие, как долго сотрудники работают
Зарплата, показывающая сколько каждый сотрудник зарабатывает
Давайте теперь погрузимся в то, как мы можем использовать метод groupby в Pandas для агрегирования данных по нескольким столбцам.
Как использовать группу Pandas с несколькими столбцами
Чтобы использовать метод groupby в Pandas с несколькими столбцами, вы можете передать список столбцов в функцию. Это позволяет вам указать порядок, в котором хотите группировать данные.
Давайте посмотрим, как это работает в Pandas:
В указанном выше блоке кода мы указали, что хотим группировать наши данные сначала по 'Role', а затем по 'Gender'. Давайте посмотрим, что происходит за кулисами, визуализируя, как это трансформирует наши данные:
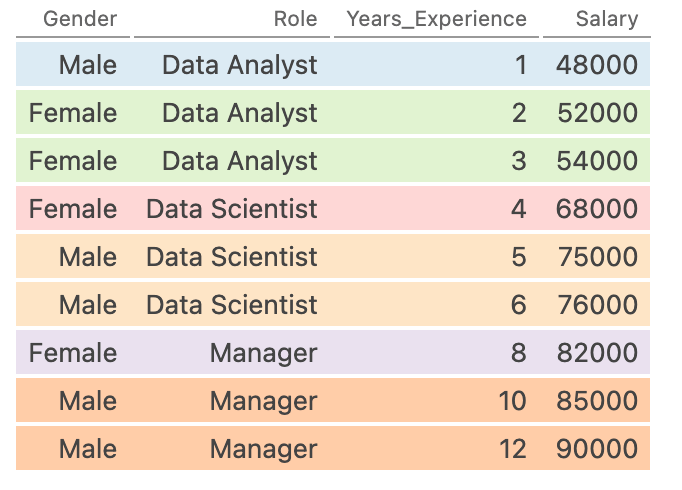
Каждый цвет представляет собой отдельную группу. В действительности, у нас есть группировка для каждой комбинации роли и пола. **Преимущество этого в том, что теперь мы можем агрегировать данные по этим группам.
Давайте теперь посмотрим, как мы можем агрегировать данные с этими группировками. Чтобы все было просто, давайте рассчитаем сумму для каждой группы по столбцу
Давайте посмотрим, что происходит под капотом при расчете данных:

Мы можем увидеть, как выглядит эти данные, распечатав их:
Мы видим, что у нас получается объект Pandas Series с несколькими индексами – по одному для каждой группировки. Теперь мы можем лучше понять общую сумму заработных плат, разделенных по ролям и по полу.
Использование Pandas GroupBy с несколькими столбцами и несколькими методами агрегации
Основываясь на том, что вы узнали в предыдущем разделе, мы также можем применять несколько агрегаций к одному столбцу, используя метод groupby Pandas с несколькими столбцами. Это позволяет вам легко анализировать данные по различным статистикам.
Для этого мы используем метод агрегирования Pandas, который позволяет настраивать способы агрегирования данных. Метод aggregate Pandas позволяет применять одну или несколько функций агрегирования к конкретным столбцам DataFrame, предоставляя суммарные статистические данные или пользовательские вычисления для этих столбцов.
Давайте рассмотрим, как мы можем рассчитать три различные статистики для нашей группировки:
Подсчет позволит нам понять, сколько сотрудников попадает в каждую группу
Сумма даст нам представление о совокупной зарплате этой группы
Среднее значение даст нам представление о средних зарплатах для каждой группы
Давайте посмотрим, как мы можем использовать метод .agg() библиотеки Pandas для вычисления нескольких агрегаций для объекта Pandas groupby:
Как и в предыдущем примере, мы можем видеть, что группировки остаются прежними, но мы смогли использовать разные методы агрегирования. Давайте посмотрим, как это работает визуально:

Мы видим, что это работает аналогично нашему предыдущему примеру. Большая разница заключается в том, что вместо возвращения Pandas Series мы на самом деле возвращаем Pandas DataFrame. Это позволяет нам легко применять различные элементы нашего более широкого набора инструментов Pandas, например, фильтрацию нашего DataFrame.
В следующем разделе вы узнаете, как использовать разные агрегаты для разных столбцов в группировке Pandas.
Использование различных агрегатов при группировке по нескольким столбцам в Panda
Сила объединения метода .groupby() с методом .aggregate() в Pandas заключается в возможности использования различных агрегаций для разных столбцов. Для этого нам нужно изменить способ использования метода aggregate(). Давайте сначала посмотрим, как изменится наш код:
В коде выше происходит довольно много всего. Но на самом деле это довольно просто:
Мы группируем наши данные таким же образом, как и раньше. Однако мы не индексируем столбец сразу. Вместо этого, мы применяем метод
.agg()непосредственно к объекту группировки.Мы передаем словарь в метод. Ключи этого словаря - это столбцы, которые мы хотим агрегировать, в то время как значения являются либо строками, либо списками строк агрегаций, которые мы хотим использовать.
Давайте рассмотрим, как мы можем использовать то, что вы только что узнали, и агрегировать несколько столбцов с помощью Pandas:
В приведенном выше блоке кода мы применили несколько агрегаций к нашим данным:
Мы рассчитали максимальное значение столбца
Также были рассчитаны среднее значение и медиана для столбца
Давайте ещё раз взглянем, как это работает изнутри:
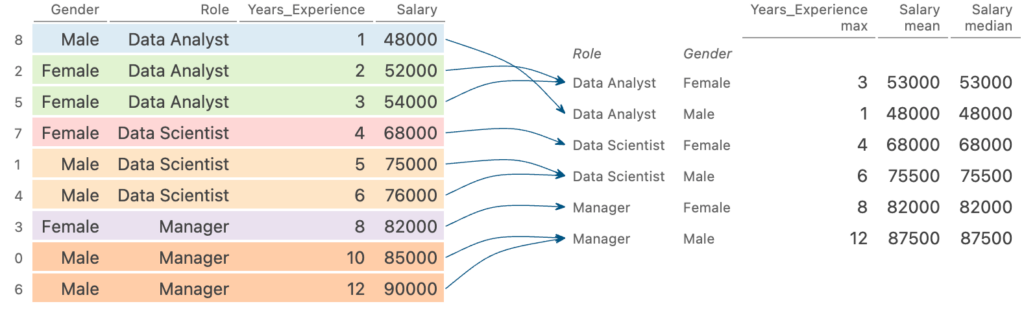
Мы видим, что это работает так же, как и в нашем предыдущем примере, возвращая DataFrame. Основное отличие заключается в том, что у нас есть не только DataFrame с мультииндексными столбцами, но и DataFrame с мультииндексными строками.
Заключение
В этом руководстве вы научились использовать метод groupby в Pandas с несколькими столбцами. Метод groupby является невероятно мощным и универсальным инструментом, который позволяет агрегировать значения аналогично операторам GROUP BY в SQL.
Вы впервые научились использовать метод .groupby() с несколькими столбцами. Затем вы научились агрегировать только один столбец при группировке по нескольким столбцам. После этого вы узнали, как указать несколько агрегаций для одного столбца. Наконец, вы узнали, как указать различные агрегации для каждого столбца при группировке по нескольким столбцам.
Дополнительные ресурсы
Чтобы узнать больше о смежных темах, ознакомьтесь с приведенными ниже учебными руководствами:
Подведение итогов и анализ кадра данных Pandas
Индексирование, выбор и присвоение данных в Pandas
Последнее обновление