
Как использовать Pandas для чтения файлов Excel в Python
В этом учебнике вы научитесь использовать Python и Pandas для чтения файлов Excel с помощью функции Pandas read_excel. Файлы Excel повсюду – и хоть они и не являются идеальным типом данных для многих исследователей данных, умение работать с ними – это необходимый навык.
К концу этого урока вы узнаете:
Как использовать функцию Pandas read_excel для чтения файла Excel
Как прочитать, укажите имя листа Excel для чтения в Pandas
Как прочитать несколько листов или файлов Excel
Как использовать определенные столбцы из файла Excel в Pandas
Как пропускать строки при чтении файлов Excel в Pandas
И более
Оглавление
Быстрый ответ: используйте Pandas read_excel для чтения файлов Excel
Для чтения файлов Excel в Pandas Python используйте функцию read_excel(). Вы можете указать путь к файлу и имя листа для чтения, как показано ниже:
В следующих разделах этого руководства вы узнаете больше о функции Pandas read_excel(), чтобы лучше понять, как настраивать чтение файлов Excel.
Понимание функции read_excel в Pandas
Функция read_excel() библиотеки Pandas имеет множество различных параметров. В этом руководстве вы узнаете, как использовать основные параметры, которые обеспечивают невероятную гибкость при чтении файлов Excel в Pandas.
io=
Путь к книге.
URL к файлу, путь к файлу и т.д.
sheet_name=
Имя листа для чтения. По умолчанию будет использоваться первый лист в книге (позиция 0).
Может считывать строки (название листа), целые числа (позиция) или списки (несколько листов)
usecols=
Столбцы для чтения, если не все столбцы должны быть прочитаны
Может быть строками столбцов, столбцами в стиле Excel («A:C») или целыми числами, представляющими позиции столбцов.
dtype=
Типы данных для использования для каждого столбца
Словарь с колонками в качестве ключей и типами данных в качестве значений.
skiprows=
Количество строк для пропуска сверху
Целое число, представляющее количество строк для пропуска
nrows=
Количество строк для анализа
Введите целое число, представляющее количество строк для чтения.
В таблице выше перечислены некоторые ключевые параметры функции Pandas .read_excel(). Полный список можно найти в официальной документации. В следующих разделах вы узнаете, как использовать вышеуказанные параметры для чтения файлов Excel различными способами с помощью Python и Pandas.
Как читать файлы Excel в Pandas read_excel
Как показано выше, самый простой способ прочитать файл Excel с помощью Pandas — просто передать путь к файлу Excel. Параметр io= является первым параметром, поэтому вы можете просто передать строку с путем к файлу.
Параметр принимает как путь к файлу, так и HTTP путь, FTP путь и другие. Давайте посмотрим, что произойдет, если мы прочитаем файл Excel, размещенный на моей странице Github.
Если вы скачали файл и посмотрели его, вы заметите, что в файле есть три листа. Как же Pandas узнает, какой лист загрузить? По умолчанию, Pandas использует первый лист (по позиции), если не указано иное.
В следующем разделе вы узнаете, как указать, какой лист вы хотите загрузить в DataFrame.
Как указать имена листов Excel в функции Pandas read
Как показано в предыдущем разделе, вы узнали, что когда лист не указан, Pandas загружает первый лист в Excel книге. В предоставленной книге есть три листа в следующей структуре:
Из-за этого мы знаем, что данные с листа “East” были загружены. Если мы хотим загрузить данные с листа “West”, мы можем использовать параметр sheet_name=, чтобы указать, какой лист мы хотим загрузить.
Параметр принимает как строку, так и целое число. Если передать строку, можно указать имя листа, который хотим загрузить.
Давайте рассмотрим, как можно указать имя листа для 'West':
Подобным образом можно загрузить лист по его позиции. По умолчанию Pandas использует позицию 0, что загружает первый лист. Допустим, мы хотим повторить наш предыдущий пример и загрузить данные из листа под названием 'West', необходимо знать где находится этот лист.
Поскольку мы знаем, что лист второй, мы можем передать индекс 1:
Мы видим, что оба этих метода вернули данные одного и того же листа. В следующем разделе вы узнаете, как указать, какие столбцы загружать при использовании функции read_excel в Pandas.
Как задать названия столбцов в Pandas read_excel
Может быть много случаев, когда вы не хотите загружать все столбцы в файле Excel. Это может быть связано с тем, что файл имеет слишком много столбцов или разные столбцы для разных листов.
Чтобы сделать это, мы можем использовать параметр usecols=. Это очень гибкий параметр, который позволяет вам указать:
Список названий столбцов
Строка с диапазонами колонок Excel
Список целых чисел, указывающих индексы столбцов для загрузки
Наиболее часто вы встретите людей, использующих список названий столбцов для чтения. Каждый из этих столбцов - это строка, разделенная запятыми, содержащаяся в списке.
Давайте загрузим наш DataFrame из приведенного выше примера, на этот раз загрузив только столбцы 'Customer' и 'Sales'
Мы видим, что передав список строк, представляющих столбцы, мы смогли проанализировать только эти столбцы.
Если мы хотим использовать изменения в Excel, мы также можем указать столбцы 'B:C'. Давайте посмотрим, как это выглядит ниже:
Наконец, мы также можем передать список целых чисел, которые представляют позиции колонок, которые мы хотим загрузить. Поскольку колонки являются второй и третьей, мы загрузим список целых чисел, как показано ниже:
В следующем разделе вы узнаете, как указать типы данных при чтении файлов Excel.
Как задать типы данных в Pandas read_excel
Pandas упрощает указание типа данных различных столбцов при чтении файла Excel. Это служит трем основным целям:
Предотвращение неправильного чтения данных
Ускорение операции чтения
Экономия памяти
Вы можете передать словарь, где ключи — это столбцы, а значения — типы данных. Это гарантирует правильное чтение данных. Давайте посмотрим, как можно задать типы данных для наших столбцов.
Важно отметить, что для этого не нужно передавать все столбцы. В следующем разделе вы узнаете, как пропускать строки при чтении файлов Excel.
Как пропустить строки при чтении Excel файлов в Pandas
В некоторых случаях вы столкнетесь с файлами, где в вашем файле Excel есть отформатированные строки с заголовками, как показано ниже:
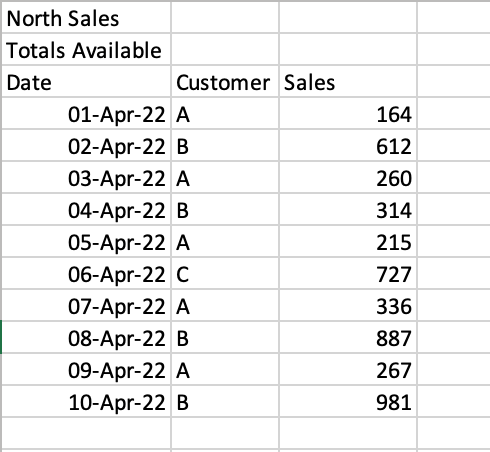
Если бы мы прочитали лист 'North', то получили бы следующий результат:
Pandas упрощает пропуск определенного количества строк при чтении Excel файла. Это можно сделать с помощью параметра skiprows=. Мы видим, что нужно пропустить две строки, поэтому мы можем просто передать значение 2, как показано ниже:
Этот метод считывает файл намного точнее! Он может быть спасением при работе с плохо форматированными файлами. В следующем разделе вы узнаете, как считывать несколько листов в Excel файле с помощью Pandas.
Как читать несколько листов в файле Excel с помощью Pandas
Pandas делает очень простым чтение нескольких листов одновременно. Это можно сделать с использованием параметра sheet_name=. В наших предыдущих примерах мы передавали только одну строку для чтения одного листа. Однако, вы также можете передать список листов для чтения нескольких листов сразу.
Давайте посмотрим, как мы можем прочитать наши первые два листа:
В приведенном выше примере мы передали список листов для чтения. Когда мы использовали функцию type() для проверки типа возвращенного значения, мы увидели, что был возвращен словарь.
Каждый лист является ключом словаря, при этом DataFrame является значением соответствующего ключа. Давайте посмотрим, как мы можем получить доступ к DataFrame 'West'
Вы также можете прочитать все листы сразу, указав sheet_name= со значением None. Аналогично, это возвращает словарь всех листов:
В следующем разделе вы узнаете, как читать несколько файлов Excel в Pandas.
Как прочитать только n строк при чтении файлов Excel в Pandas
При работе с очень большими файлами Excel может быть полезно сначала выбрать небольшой подмножество данных. Это позволяет быстро загрузить файл и лучше изучить разные столбцы и типы данных.
Это можно сделать с помощью параметра nrows=, который принимает целочисленное значение количества строк, которые вы хотите загрузить в DataFrame. Давайте посмотрим, как мы можем прочитать первые пять строк Excel
Заключение
В этом уроке вы узнали, как использовать Python и Pandas для чтения файлов Excel в DataFrame с помощью функции .read_excel(). Вы узнали, как использовать эту функцию для чтения Excel-файла, указания имен листов, чтения только определенных столбцов и указания типов данных. Далее вы узнали, как пропускать строки, читать только заданное количество строк и читать несколько листов.
Дополнительные ресурсы
Чтобы узнать больше о смежных темах, ознакомьтесь с руководствами ниже:
Таблица данных Pandas в файл CSV – экспорт с использованием .to_csv()
Объедините данные в Pandas с помощью слияния, объединения и объединения
Введение в Pandas для науки о данных
Подведение итогов и анализ таблиц данных Pandas
Последнее обновление