Тестирование и кросс-валидация
if "google.colab" in str(get_ipython()):
# удаление предустановленных пакетов из Colab, чтобы избежать конфликтов
!pip uninstall -y torch notebook notebook_shim tensorflow tensorflow-datasets prophet torchaudio torchdata torchtext torchvision
!pip install git+https://github.com/ourownstory/neural_prophet.git # может занять некоторое время
#!pip install neuralprophet # намного быстрее, но может не иметь последних обновлений/исправлений ошибок
import pandas as pd
from neuralprophet import NeuralProphet, set_log_level
set_log_level("ERROR")
Загрузить данные
data_location = "https://raw.githubusercontent.com/ourownstory/neuralprophet-data/main/datasets/"
df = pd.read_csv(data_location + "air_passengers.csv")1.Базовый уровень: обучение и тестирование модели.
1.1 Оценка Train-Test
m = NeuralProphet(seasonality_mode="multiplicative", learning_rate=0.1)
m.set_plotting_backend("plotly-static")
df = pd.read_csv(data_location + "air_passengers.csv")
df_train, df_test = m.split_df(df=df, freq="MS", valid_p=0.2)
metrics_train = m.fit(df=df_train, freq="MS")
metrics_test = m.test(df=df_test)
metrics_testMAE_val
RMSE_val
Loss_test
RegLoss_test
1.2 Прогнозирование будущего

1.3 Визуализируйте обучение
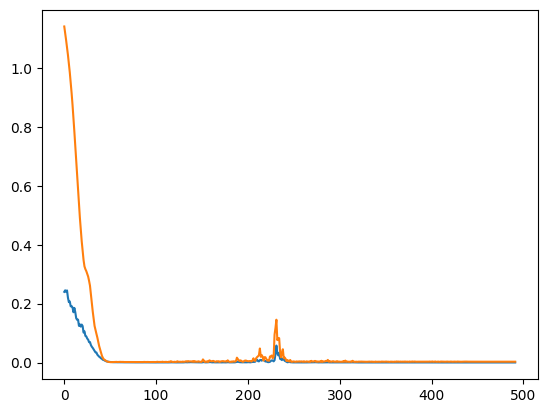
MAE_val
RMSE_val
Loss_val
RegLoss_val
epoch
MAE
RMSE
Loss
RegLoss
2. Перекрестная проверка временных рядов
MAE_val
RMSE_val
3. Расширенный уровень: трехфазное обучение, процедура проверки и тестирования.
3.1 Обучение, проверка и тестирование оценки
MAE
RMSE
Loss
epoch
split
MAE_val
RMSE_val
Loss_test
RegLoss_test
3.2 Обучение, перекрестная проверка и перекрестное тестирование
MAE
RMSE
MAE_val
RMSE_val
MAE_val
RMSE_val
Last updated